FAQ 汇总 #
格式要求: #
问答类 #
不涉及具体方案步骤和流程性的问题可以参考如下格式。
问:(不涉及具体方案和流程性问题)
答:(判断、对错、简要知识点)
操作类 #
一些问题排查,涉及到问题现象、原因分析、解决方案等内容的 FAQ 可以参考如下格式。
问题现象
简单描述遇到的问题的操作、所用软件的版本、报错关键日志/错误码/抛出的异常等信息,方便参考及复现。
可能原因
描述可能导致该问题的原因。
解决方案
描述解决该问题的方法或临时规避手段。
问题之间使用 --- 进行分割。
问答 #
知识点 #
问:社区版 OceanBase 数据库支持 IPv6 网络吗?
答:当前版本暂不支持,预计 OceanBase 数据库 4.2 版本支持。
问:OceanBase 数据库 4.x 版本支持哪几种备份介质?
答:目前已支持 NFS、阿里云 OSS、腾讯云 COS。
问:OceanBase 数据库 4.0 版本触发器、存储过程、自定义函数最大支持长度是多少?
答:触发器最大支持 65536 字节,存储和自定义函数 clob 类型存储,基本可理解为无上限。
问:OceanBase 数据库的主键是否是聚簇索引?
答:是的。
问:OceanBase 数据库 4.x 版本如何进行 rs 切主?
答:可执行ALTER SYSTEM SWITCH REPLICA leader LS=1 SERVER='目标ip:rpc_port' TENANT ='sys';命令进行切主,示例如下。`ALTER SYSTEM SWITCH REPLICA leader LS=1 SERVER ='xx.xx.xx.xx:2882' TENANT ='sys';`
问:OceanBase 数据库是否能只进行数据备份,不做日志备份呢?
答:进行数据备份前提是开启日志备份,不支持只做数据备份。
问:为什么刚部署的 OceanBase 数据库,数据和日志磁盘占用 90%,或者占用很大?
答:OceanBase 数据库的数据和日志目录采用的是预占用机制,只能动态增加占用大小,暂不支持缩小。不过 OceanBase 数据库 4.1 版本支持 log_disk_size 动态扩缩。OceanBase 数据库 4.x 版本磁盘预占用相关参数为:
数据磁盘:datafile_size / datafile_disk_percentage
日志磁盘:log_disk_size / log_disk_percentage
问:下划线开头格式的参数为隐藏参数,无法通过 SHOW PARAMETERS 语句来查询?
答:可通过如下命令查看。`SELECT * FROM oceanbase.__all_virtual_sys_parameter_stat WHERE name='_ob_enable_prepared_statement';`
问:如何清理租户并释放空间?
答:先执行drop tenant xxx force;命令删除租户,再执行drop resource pool xxx;命令删除对应的资源池。
两条命令均成功执行才算释放空间。但需注意该操作会清理租户下的所有数据。
问:MySQL 迁移到 OceanBase 数据库还需要用 ShardingSphere 做分库分表吗?
答:不需要,OceanBase 数据库本身支持分区表,可以通过分区表设计业务。
问:主机资源够的情况下,多个 Server 可以部署在同一台主机吗?
答:手动部署和使用 OBD 部署均支持该场景,使用 OCP 部署不支持该场景。如果使用 OBD 工具部署需使用obd cluster deploy命令修改端口和安装目录。但生产环境不建议如此部署,单服务器单 observer 进程最佳。
问:使用 OBD 部署社区版三节点集群,必须使用 admin 用户吗?
答:非强制要求,但是建议使用 admin 用户部署,后期 OCP 接管的集群需要是使用 admin 用户部署的 OceanBase 数据库。
问:使用 OceanBase 数据库社区版 3.x 部署一个读写分离的集群时,可以部署 4 个 Zone,其中 3 个 Zone 是全能型副本,一个 Zone 是只读的副本吗?
答:建议 Zone 的数量最好是奇数,以 3 个 Zone 或 5 个 Zone为主。
问:手动部署的 OceanBase 数据库可以用 OBD 管理吗?
答:不支持。
问:OMS 可以搭建集群吗?
答:目前社区版 OMS 3.3.1 版本支持集群化部署,低于此版本不支持。
问:社区版 MySQL 模式的 JDBC 驱动在哪下载?
答:如果使用 OceanBase 数据库的 MySQL 模式,推荐使用 MySQL JDBC 驱动 5.1.47 版本。
如果使用企业版 OceanBase 数据库的 Oracle 模式,可从 Maven 中央仓库 下载的 OceanBase 数据库的 JDBC 驱动。
问:使用 SpringBoot 连接 OceanBase 数据库的正确写法是什么?
答:可以参考 MySQL 连接方式,区别在于通过直连 OBServer 节点连接时 username 写法是用户名@租户名,通过 OBProxy 代理连接时 username 写法是用户名@租户名#集群名。
问:OBD 部署失败,怎么清理配置和目录?
答:
1)命令方式:`obd cluster destory 部署名称,销毁会清理相关目录。
2)后台方式:杀掉所部署组件相关进程(ps -ef|grep observer),按部署配置文件里配置路径删除安装、数据、日志目录,并检查目录所属用户权限是否正确即可重新部署。
问:OCP 的 Docker 容器是否为无状态?
答:无状态,数据保留在部署在宿主机上的 metadb(单机/集群OceanBase 数据库)中。
问:内部表和内部虚拟表是什么?
答:内部表一般指系统表,虚拟表只是系统表中的一部分,ID 号介与 10000~20000 之间。
问:备份数据时候,需要每个 OBServer 节点都挂载 NFS 吗?
答:是的。
问:备份可以备份单个租户的么?
答:OceanBase 数据库 3.x 版本只支持集群备份,4.0 版本起支持租户级别备份,且不再支持集群级别备份。
问:副本保持同步是通过同步 clog 吗?
答:是的,以分区为单位做 clog 副本同步,只有分区的主副本才能进行更新,如果有多个分区的主副本同时在更新,仍然以分区为单位做 Paxos 同步。
问:社区版 OceanBase 数据库怎么查看哪些表是复制表?
答:3.x 版本中通过所示命令查看。`select table_name from oceanbase.__all_table_v2 where duplicate_scope=1;`4.x 版本中预计 4.2 版本才支持。
问:OceanBase 数据库 4.0 版本中,CDB 开头的视图、DBA 开头的视图、GV 开头的视图,这些是什么规则?
答:CBD 开头的是 sys 租户的视图,能看到全局的信息。DBA 开头的视图只能看到租户自己的信息。gv$ 一般和 v$ 一起,直连数据库节点的时候,v$ 只能看到本机器,gv$ 是所有机器节点的信息。
问:OceanBase 数据库 4.0 版本,普通用户租户查看自己租户下所有的表,该查哪个视图?
答:先执行select distinct(OBJECT_TYPE) from DBA_OBJECTS;命令查询表类型。
后执行select OBJECT_NAME from DBA_OBJECTS where OBJECT_TYPE='table' ;命令根据表类型查表名。
问:执行
obd cluster list命令显示状态为destroyed的集群怎么清理删除?
答:cd ~/.obd/cluster,删除集群对应的 Name 目录。
问:社区版 OCP 开源的吗?
答:目前工具开放供下载使用,不开源,后续轻量版 OCPExpress 会考虑开源。
问:hint 中的 NO_USE_PX 是什么?
答:NO_USE_PX 指的是关闭并行查询。OceanBase 数据库 4.x 版本暂不支持关闭并行查询功能。
问:X86 版本 OCP 是否支持接管 ARM 版本的 OceanBase 数据库集群?
答:不支持混合接管和部署。
问:OceanBase 数据库支持 openeuler(欧拉)部署么?
答:暂未进行兼容适配,能部署但不保证运行后功能可靠性。
问:OceanBase 数据库一个表的分区大小是否有推荐大小?
答:OceanBase 数据库对分区大小未做限制,一般建议一个分区大小不要超过 100G,分区大小也可以按照磁盘空间和分区数预估。
问:proxy_sessid 和 server_sessid 之间的关系是什么?
答:proxy_sessid 唯一标识客户端和 OBProxy 之间的连接,server_sessid 唯一标识 OBPrxoy 和 OBServer 之间的连接。
问:OBClient是不是没有 ubuntu/debian 系统的版本?
答:暂不支持,可使用 MySQL 客户端。
问:社区版 OMS 是否支持将 MySQL 数据库数据迁移到企业版 OceanBase 数据库的 MySQL 租户?
答:不支持。
问:OceanBase 数据库 4.0 版本怎么查看锁和事务的信息?
答:可在 DBA_OB_DEADLOCK_EVENT_HISTORY 中查看。
问:怎么查租户表占用磁盘空间大小?
答:仅查询基线数据的,转储合并后能看到最新的占用大小
OceanBase 数据库 3.x 版本可执行select tenant_id, svr_ip, unit_id, table_id, sum(data_size)/1024/1024/1024 size_G from __all_virtual_meta_table group by 1, 2, 3, 4;命令。
OceanBase 数据库 4.x 版本可执行select sum(size)/1024/1024/1024 from (select DATABASE_NAME,TABLE_NAME,TABLE_ID,PARTITION_NAME,TABLET_ID,ROLE from DBA_OB_TABLE_LOCATIONS ) AA full join (select distinct(TABLET_ID) ,size from oceanbase.GV$OB_SSTABLES ) BB on AA.TABLET_ID=BB.TABLET_ID where AA.role='leader' and AA.table_name='table_name';命令。
问:OceanBase 数据库 4.0 版本 TRUNCATE TABLE 支持指定分区清除数据吗?
答:支持,具体清理分区类型参见官网 OceanBase 数据库文档 Truncate 分区。
问:OBD 和 OBProxy 能和 OceanBase 集群部署在一起么?有什么性能影响?
答:可以,OBD 和 OBProxy 占用资源很少,业务量或者节点数不大情况下,几乎没什么性能影响。如果是大规模生产环境建议单独节点部署 OBProxy。
问:PHP 怎么连接 OceanBase 数据库?
答: https://github.com/oceanbase/oceanbase/issues/841。
问:执行
obd cluster destory命令销毁集群后能否再恢复?
答:不能,该操作直接删除物理数据文件,如果存在备份文件,可以新建集群备份恢复。
问:mysql-connector-java 的 8.x 版本怎么连接 OceanBase 数据库?
答:使用 MySQL Connector/J 8.x 版本连接 OceanBase 数据库时,Class.forName("com.mysql.jdbc.Driver")中的 com.mysql.jdbc.Driver 需要替换成 com.mysql.cj.jdbc.Driver。
问:是否有 JDBC 连接 OceanBase 数据库的配置示例?
答:conn=jdbc:oceanbase://x.x.x.x(ip):xx(port)/xxxx(dbname)?rewriteBatchedStatements=TRUE&allowMultiQueries=TRUE&useLocalSessionState=TRUE&useUnicode=TRUE&characterEncoding=utf-8&socketTimeout=3000000&connectTimeout=60000
问:社区版 OCP 支持 RHEL8 吗?
答:支持 RHEL7.2 及以上版本。
问:OceanBase 数据库是否支持主键修改?
答:3.x 版本不支持,4.x 版本支持。
问:Datax 的 ob writer 里 obWriteMode 支持 insert ignore 吗?
答:不支持,可以采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句。
问:如何查看所有的 SQL 记录?
答: OceanBase 数据库 3.x 版本可通过 SQL 审计视图 gv$sql_audit 查看。 OceanBase 数据库 4.x 版本可通过 SQL 审计视图 gv$ob_sql_audit 查看。
问:OceanBase 数据库 4.0 版本合并表信息是哪些?
答:major freeze 相关的信息放到了 __all_merge_info(用于存放租户合并的整体 merge 信息)、__all_zone_merge_info(用于存放租户下每个 Zone 的 merge 信息)表中。
__all_merge_info 表中有合并版本号、合并状态、是否发生了 error 等信息。 除了 sys 租户外,每个用户租户对应的 meta 租户下都有这两张表,用于保存该用户租户和 meta 租户的 merge 信息。也可以在 sys 租户下通过查看CDB_OB_MAJOR_COMPACTION来查看所有租户的 __all_merge_info 信息,通过查看CDB_OB_ZONE_MAJOR_COMPACTION来查看所有租户的 __all_zone_merge_info 信息。
OceanBase 数据库 4.0 支持对每个租户单独设置合并时间点,相关配置项为 major_freeze_duty_time,系统租户下可执行alter system set major_freeze_duty_time = 'xxx' tenant sys;语句设置。
问:OceanBase 数据库 4.0 版本为什么取消了轮转合并?
答:4.0 版本将合并拆分成了租户级,粒度更小,执行时间更短,因此取消了轮转合并。
问:如何手动杀掉正在执行 SQL?
答:执行show processlist;命令查看 ID 后执行kill $ID;命令。
原理 #
问:OceanBase 数据库的索引采用的是哪种方式?
答:MemTable 使用的是 B+ 树结构,而 SSTable 使用的是宏块结构。
问:plan cache 分配资源过少或者大并发会造成 plan cache 命中率较低的问题吗?
答:根据资源和并发情况分为如下几种情况讨论。
- 资源少的情况下需要看流量
- 如果流量一直只是一个 query,那么这个 plan 将一直存在 plan cache 中,而且一直命中。
- 如果流量是多种多样的 query,那么由于资源分配有限,plan 将会发生频繁汰换,最终分配资源过少会导致 plan cache 命中过低的。
- 并发量大导致内存快速写满会造成 plan 的频繁汰换,这将导致计划命中率降低。但是需要注意的是并发量大不一定会导致 plan cache 命中率降低,只要汰换率没有上去,命中率也不会降低。
问:租户 MemStore 使用达到阈值后,选择合并或者转储的依据是什么?
答:有自动转储和手动转储两种转储方式。有自动合并、定时合并与手动合并三种合并方式,如果自动合并过程中失败了,除了个别错误外,会一直重试。合并在默认情况下是以每日合并的方式定时触发的。
- 自动转储是当 MemStore 使用达到预设的限定时,例如 MemStore 内存使用率大于
memstore_limit_percentage * freeze_trigger_percentage的值,自动触发冻结 + 转储,转储为 mini sstable 后根据 minor_compact_trigger 来触发 mini minor 或 minor 。- 手动转储是手动执行
alter system minor freeze;进行转储。
问:parallel_servers_target 并发参数怎么理解?
答:parallel_servers_target 这个指标都是针对 px 类型的 SQL 进行约束的,当超过这个阈值,阻塞的是后续的 px 类型 SQL 的执行,不阻塞本地 SQL 的执行。也就是并发 SQL 不会占用所有线程,会给普通 SQL 预留一些线程资源。所以 parallel 数量的设置应该根据需求和资源来确定,如果全都设成并发 SQL,就会互相阻塞。
问:用户的 SQL 请求和 RPC 之间有什么关系?
答:OBServer 节点之间沟通使用的是 RPC 2882 端口,最简单的以广播查询 SQL,是建立一张分区表,但是 SQL 语句不带分区键,用户执行 SQL 是发到了一台 OBServer 节点机器上,但是分区表的各个分区的主副本是在多台 OBServer 节点机器上的,需要将OceanBase 数据库接收 SQL 的请求拆分,调用各个分区主副本所在的 OceanBase 数据库获取数据,然后再聚合后返回给用户。
问:GLOBAL 的变量会持久化到什么地方?
答:仅 GLOBAL 级别的变量会持久化,SESSION 级别的变量不会进行持久化。持久化到内部表与配置文件,可以在 /home/admin/oceanbase/etc/observer.config.bin 与 /home/admin/oceanbase/etc/observer.config.bin.history 文件中查询配置项
问:OceanBase 数据库 4.0 版本中,GV$OB_SERVER_SCHEMA_INFO 视图中的 SCHEMA 是什么?
答:Oceanbase 数据库的 schema 泛指一切需要在集群范围内同步的数据库对象元信息,包括但不限于 table、database、user 等元信息。此外 Oceanbase 数据库的 schema 是多版本且各租户独立,在集群范围同步是最终一致的。
GV$OB_SERVER_SCHEMA_INFO 可以理解为每台 OBServer 节点机器中每个租户已经刷新的最新版本的 schema 的信息,这个视图用户比较关注的 schema 信息是 REFRESHED_SCHEMA_VERSION、SCHEMA_COUNT、SCHEMA_SIZE,其含义如下。
- REFRESHED_SCHEMA_VERSION:对应租户在对应机器已刷新到的 schema 版本。
- SCHEMA_COUNT:对应 schema 版本下,各 schema 对象数目的总和。
- SCHEMA_SIZE:对应 schema 版本下,各 schema 对象总共所占的内存大小(单位 B)。
问:执行计划中的 px partition iterator,px block iterator 是什么意思?
答:partition iterator 是以分区粒度迭代数据,block iterator 是以 block 粒度迭代数据,Iterator 是对数据的抽象,它把数据抽象成一块一块的,以便多个线程并发地处理这些数据。一块数据如果对应的是一个分区,则是 partition iterator。一块数据如果对应的是一个或数个宏块,则是 block iterator。
问:OceanBase 数据库是如何创建索引,不影响更新操作的?
答:OceanBase 数据库在创建索引的时候,是一个渐进的过程,首先不影响写入,因为 OceanBase 数据库是追加写。对于索引列有更新的情况,会进行记录。然后会去扫描现有数据去创建索引,扫描完成之后将更新的和新增的数据做一次合并,最后再将索引标记为可用状态,就完成了索引的创建。
问:OceanBase 数据库 4.0 版本生产环境最小磁盘使用空间限制为什么是 54G?
答:54G 是目前计算出来 OceanBase 数据库启动需要的空间,下面是计算公式。
slog 统计规则:slog 统计 10G,目前是硬编码,有计划优化到 2G、4G左右。
SSTable 统计规则:空集群启动后转储合并实测大概会有 1G 磁盘开销,代码没有针对 SSTable 做限制,但是按照长稳运行需要 20G。
clog 统计规则如下。
- 理论最小值:新建一个租户预期需要创建 4 个日志流,每个日志流目前空间需求最低 512M,这里算出需要的最小磁盘是 2G。
- 用户设置值:系统租户:取 max(2G,用户设置);普通租户:取 max(2G,所在盘全部)。
- OBD计算:根据 OceanBase 数据库最小规则(4C8G)计算,即 8 * 3 = 24,其中 3 为 OceanBase 数据库中 4.x 中对于 clog 内存和磁盘占用的大概估算。
所以目前,选了 24G+10G+20G = 54G 作为启动最小依赖的内存,不过后续有优化的计划。
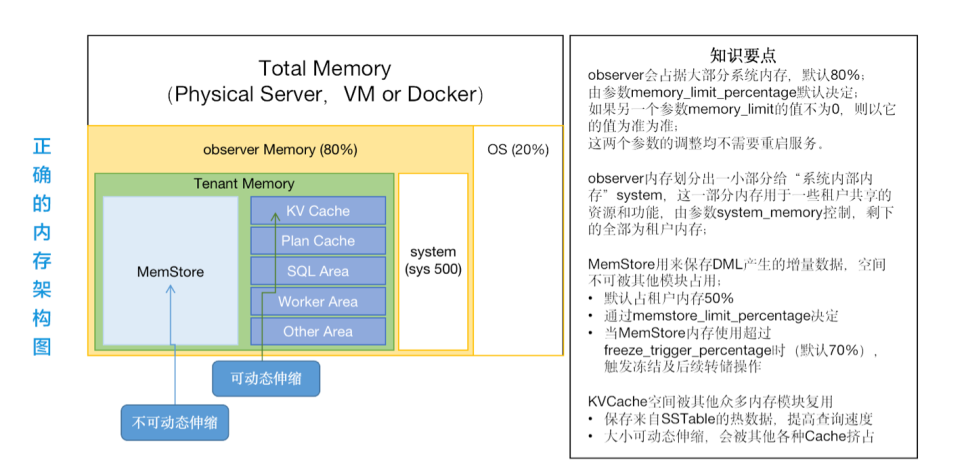
问:OceanBase 数据库内存是怎么规划的?
答:
问:OceanBase 数据库中 SQL 执行流程
答: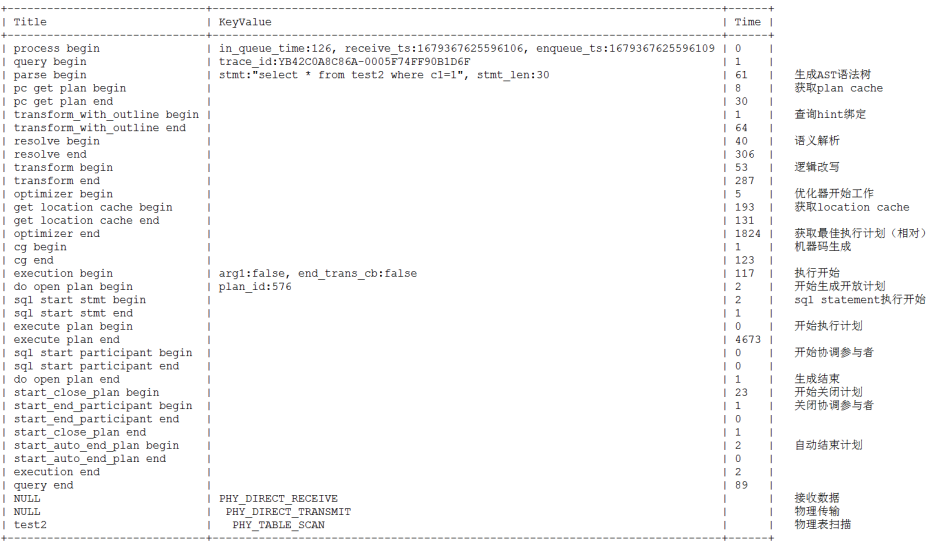
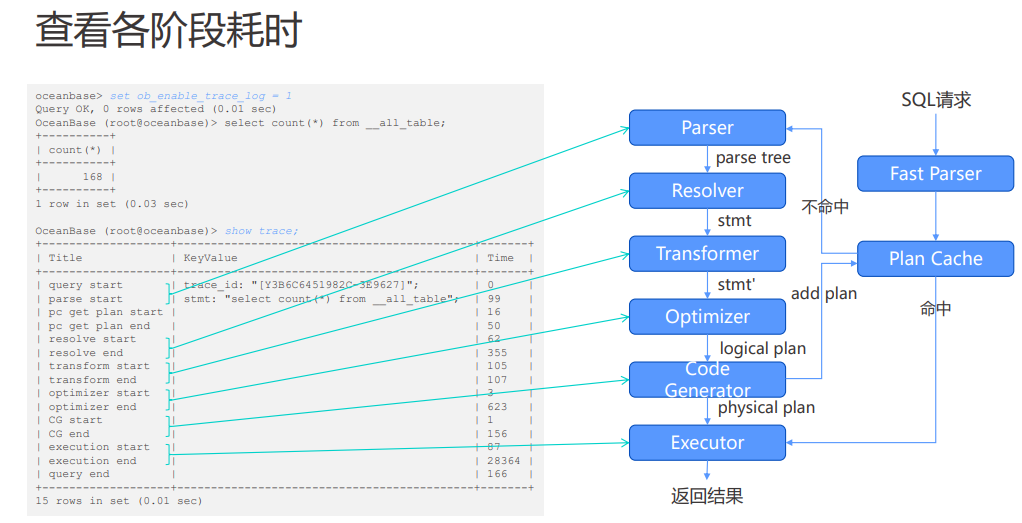
报错 #
问:oblogproxy 的 config.setTableWhiteList(“sys.abc.*”) 如何设置指定表的信息?
答:使用|分隔符,例如sys.abc.tableA|sys.abc.tableB。
问:OceanBase 数据库 V3.1.0 升级到 V3.1.4 版本失败?
答:OceanBase 数据库 V3.1.0不支持本地升级,只能做数据迁移逻辑升级,并且 3.x 版本不支持直接升级至 4.x 版本。
问:报错 OceanBase 数据库 D-1006: Failed to connect to oceanbase-ce 的原因是什么?
答:有如下几种情况。
- OBD 和目标机器之间网络不连通。
- 对应的组件进程已经退出或者不提供服务。
- 账号密码不匹配。
- OceanBase 数据库日志磁盘不足。
问:报错 oceanbase-ce’s servers list is empty 的原因是什么?
答:检查部署配置文件 oceanbase-ce 模块下的 servers 中 ip 格式是否填写正确。
问:使用 OBLOADER 导入数据失败,未返回报错怎么办?
答:OBLOADER 默认的行为是:运行错误日志记录在 logs/ob-loader-dumper.error,具体错误的记录会记录在 logs/ob-loader-dumper.bad。
如果要求遇到错误快速失败,可以指定 –max-errors 选项。
问:OCP 界面无操作退出登陆,怎么设置超时时间?
答:默认是 30m 无操作退出,可在 OCP 系统参数中设置 server.servlet.session.timeout。
问:OCP 上集群状态显示运维中?
答:“任务”中可能有任务在执行或执行失败。
问:用 benchmarksql 导入数据时,出现如下 3 类错误。
- Worker 089: ERROR: Failed to init SQL parser
- Worker 044: ERROR: No memory or reach tenant memory limit
- Worker 083: ERROR: Internal error 答:首先看下相关日志文件,如 benchmarksql.log。
- 确认使用的租户,因为 sys 租户内存太小,很可能不够用,所以不建议使用 sys 租户。 可通过命令
select a.tenant_id,max(tenant_name), round(sum(used)/1024/1024/1024,2) “mem_quota_used(G)” from gv$memory a, __all_tenant b where a.tenant_id=b.tenant_id;查询,如果查询结果 tenant_id > 1000 则是普通租户,这样可以判断租户的情况。- 如果是普通租户,查看 memory_limit 的值是不是太小,建议调大些。
- 查看 props.ocenbase 配置文件,里面配置了很多测试的配置信息,比如数据库,仓库数等等。props.oceanbase 文件中参数 warehouses 和 loadWorkers 的值需要修改成较小的值,然后登录(用 user 参数值登录),再测试一下,如果没问题,说明测试资源不足,可能是租户资源,也可能是机器资源有问题,此时可以参考租户资源和机器配置分析原因。
故障恢复 #
问:服务器硬件故障或者需要长时间停止某个节点或某个 Zone,怎么操作?
答:需要调整 server_permanent_offline_time 参数,防止被永久下线。默认是 1 小时。该配置项的适用场景及建议值如下。
- OceanBase 数据库版本升级场景:建议将该配置项的值设置为 72h(OCP 升级 OceanBase 数据库可忽略,默认会调整)。
- OceanBase 数据库硬件更换场景:建议手动将该配置项的值设置为 4h。
- OceanBase 数据库清空上线场景:建议将该配置项的值设置为 10m,使集群快速上线。
问:创建分区表报错 Too many partitions (including subpartitions) were defined?
答:有如下两个原因。
- 超出单表最大分区数限制(8192个)。
- 租户内存不足。
问:系统租户 root@sys 用户密码忘记了?
答:根据部署方式的不同有两种方法。
- OCP 部署时可对应集群总览界面 - 修改密码。
- OBD 部署时可执行
obd cluster edit-config 部署名称命令查看配置文件中的密码信息。

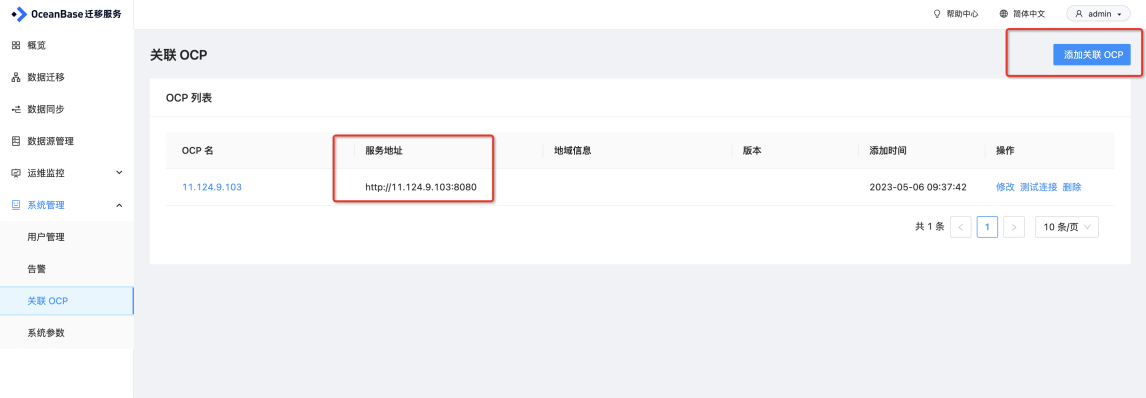
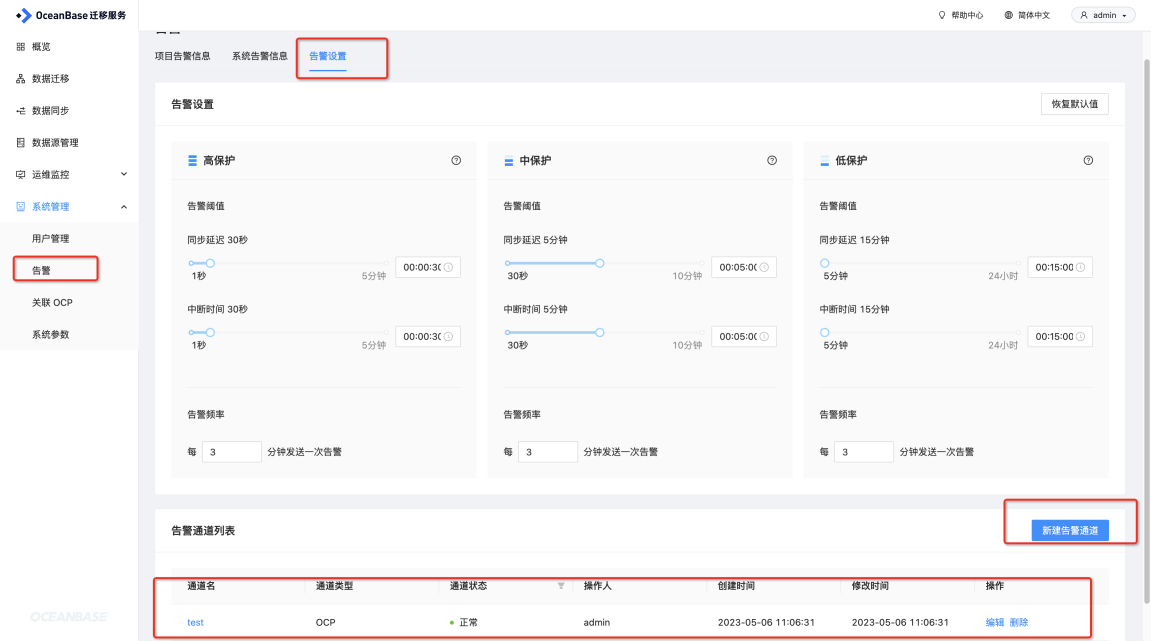
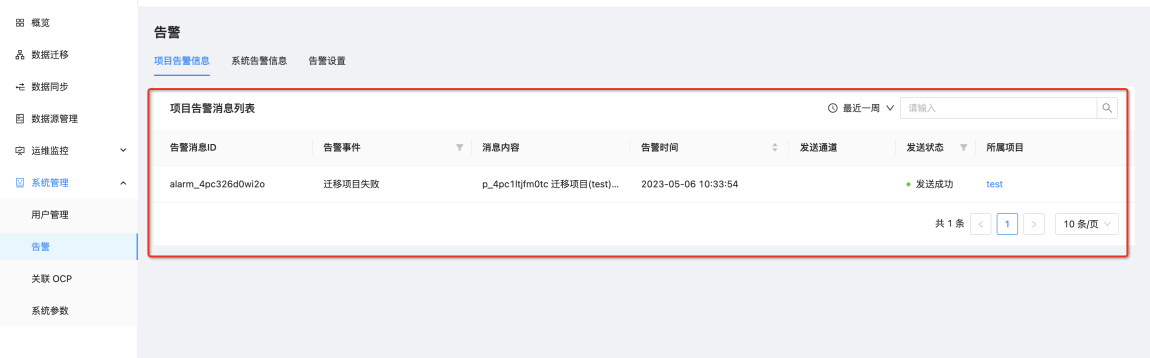
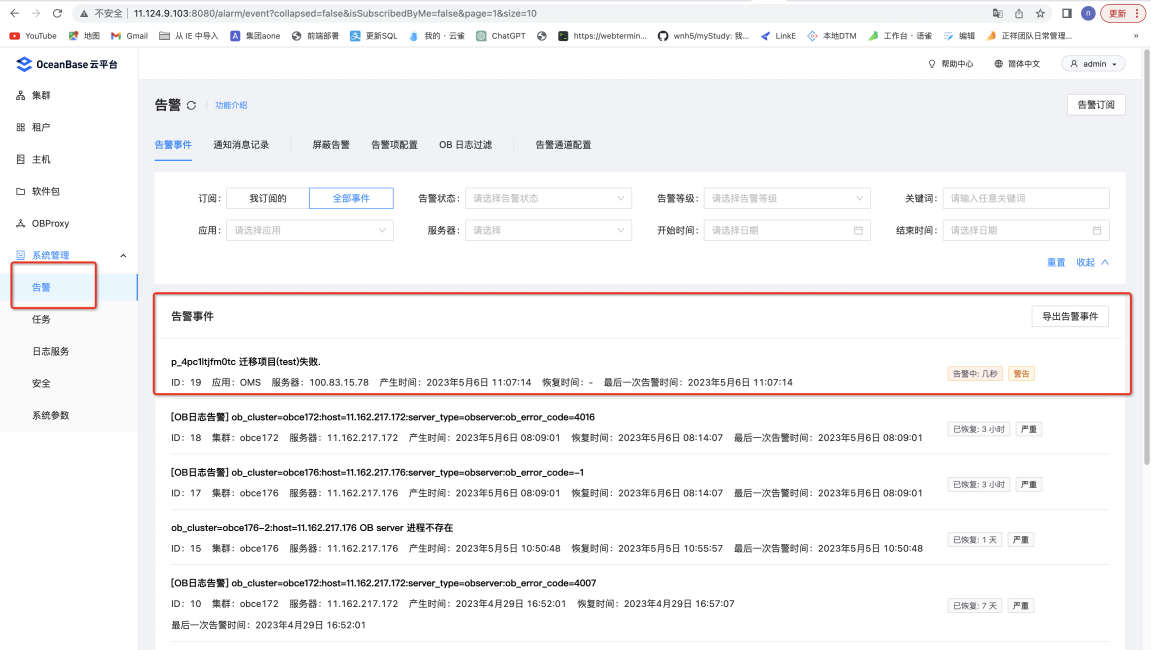
问:OCP 怎么关联 OMS 的告警信息?
答:
- OMS 上添加关联 OCP
- OMS 上新建告警通道
- OMS 告警信息如下
- ocp 同样能收到告警
性能调优 #
问:explain 预估耗时不准,有具体过程执行耗时吗?
答:可以查看视图表 gv$sql_plan_monitor。
问:亿级别数据创建索引耗时超长怎么优化?
答:增加并行加快索引创建,设置并发SET GLOBAL OB_SQL_WORK_AREA_PERCENTAGE = 30; --- 增加SQL执行内存百分比 SET SESSION_FORCE_PARALLEL_DDL_DOP = 32; --- 设置DDL并行度 SET GLOBAL PARALLEL_SERVERS_TARGET = 64; --- 并行度增加需要设置该参数,比所有并行度和大即可,所有 DDL 的并行度加起来不超过租户 max_cpu 的上限 ALTER SYSTEM SET _TEMPORARY_FILE_IO_AREA_SIZE = '5'; --- 调大临时文件内存缓存,建议小于10 -- 如果有限流可以关闭 关闭 IO 限流:alter resource unit xxxx max_iops=10000000, min_iops=10000000; --- 1 个 Core 对应 1 万 IOPS 的值 关闭网络限流:alter system set sys_bkgd_net_percentage = 100; --- 默认60
问:大数据量插入如何提高效率?
答:可以从应用层、数据库层、工具层三个层面提高。
- 应用层: jdbc url 上开启批量参数,重写批量,ps 缓存相关参数打开。
cacheServerConfiguration=true rewriteBatchedStatements=true useServerPrepStmts=true cachePrepStmts=true当然代码也是要 addBatch,executeBatch。
- 数据库层:
- OceanBase 数据库 4.1 版本支持旁路导入,详情请参见官网 OceanBase 数据库文档 旁路导入概述。
- 4.x 版本支持并行导入,详情请参见官网 OceanBase 数据库文档 体验并行导入 & 数据压缩。
- 工具层: 使用 OBLOADER 导数工具,并按需进行调优,详情请参见官网 OceanBase 导数工具文档 性能调优。
问:OceanBase 数据库系统日志打印太大太多怎么办?
答:可参考如下命令优化。# 进入 OceanBase 数据库的日志目录 cd ~/observer/log # 删除 wf 和日期结尾的日志 rm -f observer*.wf observer.log.2023* # 登录系统租户(root@sys),设置系统日志参数 alter system set enable_syslog_recycle=true -- 开启日志回收 alter system set enable_syslog_wf=false --关闭 wf 日志打印 alter system set max_syslog_file_count=10 --限制日志个数,按需调整(单个日志 256M) alter system set syslog_level ='ERROR'; --设置系统日志级别(DEBUG/TRACE/INFO/WARN/USER_ERR/ERROR),生产环境建议保持 INFO 级别,方便问题排查定位。
问:OBProxy日志打印太大太多怎么办?
答:可使用系统租户(root@sys)或者 root@proxysys 连接 OceanBase 集群执行如下命令修改。show proxyconfig like '%log_file_percentage%'; alter proxyconfig set log_file_percentage=75;以下是 OBProxy 日志相关参数。
参数 默认值 取值范围 解释 log_file_percentage 80 [0, 100] OBProxy 日志百分比阈值。超过阈值即进行日志清理。 log_dir_size_threshold 64GB [256MB, 1T] OOBProxy 日志大小阈值。超过阈值即进行日志清理。 max_log_file_size 256MB [1MB, 1G] 单个日志文件的最大尺寸。 syslog_level INFO DEBUG, TRACE, INFO, WARN, USER_ERR, ERROR 日志级别。
问:OceanBase 数据库怎么开启慢查询记录?
答:SQL 执行时间默认情况下超过 1s 就会记录到 observer.log 日志或者在 OCP 白屏监控有记录。该配置受租户参数trace_log_slow_query_watermark控制,可通过如下命令修改配置。-- 查看参数配置 show parameters like '%trace_log_slow_query_watermark%'; -- 修改参数 alter system set trace_log_slow_query_watermark='2s';
问:如何查看某个实例(租户)下库表分区主副本的位置和大小?
答:根据不同版本有如下两种方式。
OceanBase 数据库 3.x 版本,执行如下命令。
SELECT t.tenant_id, a.tenant_name, t.table_name, d.database_name, tg.tablegroup_name , t.part_num , t2.partition_id, t2.ZONE, t2.svr_ip , round(t2.data_size/1024/1024/1024) data_size_gb , a.primary_zone , IF(t.locality = '' OR t.locality IS NULL, a.locality, t.locality) AS locality FROM oceanbase.__all_tenant AS a JOIN oceanbase.__all_virtual_database AS d ON ( a.tenant_id = d.tenant_id ) JOIN oceanbase.__all_virtual_table AS t ON (t.tenant_id = d.tenant_id AND t.database_id = d.database_id) JOIN oceanbase.__all_virtual_meta_table t2 ON (t.tenant_id = t2.tenant_id AND (t.table_id=t2.table_id OR t.tablegroup_id=t2.table_id) AND t2.ROLE IN (1) ) LEFT JOIN oceanbase.__all_virtual_tablegroup AS tg ON (t.tenant_id = tg.tenant_id and t.tablegroup_id = tg.tablegroup_id) WHERE a.tenant_id IN (1006 ) AND t.table_type IN (3) AND d.database_name = 'T_FUND60PUB' -- 库名 and table_name in ('BMSQL_HISTORY') -- 表名 ORDER BY t.tenant_id, tg.tablegroup_name, d.database_name, t.table_name, t2.partition_id;OceanBase 数据库 4.x 版本,执行如下命令。
select svr_ip,count(1) from__all_virtual_ls_meta_table where tenant_id=1002 groupby svr_ip;
OBD 部署问题 #
问题现象
使用 OBD 部署 OceanBase 数据库 V3.1.4 时提示 Warn 级别报错信息
[WARN] (x.x.x.x) clog and data use the same disk (/),安装流程可正常进行,程序正常。可能原因
生产环境下要求数据目录和安装目录配置为不同盘。小规模且短期的测试环境可以忽略,生产环境必须保证安装目录、数据目录、日志目录均是分盘目录,否则后期使用会出现非业务数据占满磁盘而出现磁盘使用率满问题。
解决方案
可执行
obd cluster edit-config xxx命令编辑配置文件,将 data_dir 和 redo_dir 设置为不同磁盘目录,保存后根据黑屏输出执行对应命令。
问题现象
使用 OBD 部署 OceanBase 集群后,通过 OBProxy 登录数据库报错
ERROR 2013 (HY000): Lost connection to MySQL server at ‘reading authorization packet’。可能原因
配置文件中 proxyro_password 和 observer_sys_password 两个配置项设置未保持一致。
解决方案
可执行
obd cluster edit-config xxx命令编辑配置文件,将配置项 proxyro_password 和 observer_sys_password 保持一致,保存后之后根据黑屏输出命令执行即可。
问题现象
使用 OBD V1.6.0 部署 OceanBase 数据库时报错
Open ssh connection x。可能原因
机器之间跳转使用配置文件中的 user 模块下的 ssh 连接信息,无法连接可能是未配置或配置用户信息不正确等。
解决方案
可查看 config.yaml 内关于 user 部分设置是否正确。若使用的 password 的方式,可尝试下手动使用改密码和对应用户能否登录到对应机器。
问题现象
OBD V2.0.0 中执行 obd web 命令后无法访问到白屏部署界面。
可能原因
- 防火墙问题
- 其他安全程序禁止 IP 或端口访问
- 内外网环境,部署使用内网 IP,访问需要使用外网 IP
- obd web 进程被手动杀掉
- 离线网络环境,未关闭远程仓库,导致8680端口未起
解决方案
您可检查是否是上述原因引起,并根据具体原因进行处理。
问题现象
执行
obd cluster deploy obce-single -c obce-single.yaml命令不成功,报错[ERROR] Failed to download [mirrors.aliyun.com/oceanbase/community/stable/el/None/aarch64///repodata/repomd.xml](http://mirrors.aliyun.com/oceanbase/community/stable/el/None/aarch64///repodata/repomd.xml) to /home/admin/.obd/mirror/remote/OceanBase-community-stable-elNone/repomd.xml后执行
obd cluster list命令查看 Cluster 状态是 configured。可能原因
OBD 默认开启远程镜像下载,无法联网环境将下载失败,需要关闭远程镜像获取,将安装包导入本地仓库,本地安装即可。
解决方案
执行
obd mirror disable remote命令禁用远程镜像仓库,并执行obd mirror clone命令将安装包复制本地仓库。
问题现象
使用 OBD 部署 OceanBase 数据库 V3.1.3 时报错 NTP 服务未同步
[ERROR] Cluster NTP is out of sync。可能原因
使用 OBD 部署时做了时差校验,当服务器之间时差超过 100ms 时,会出现 Root Server 无主情况。
解决方案
安装 NTP,进行时钟同步。
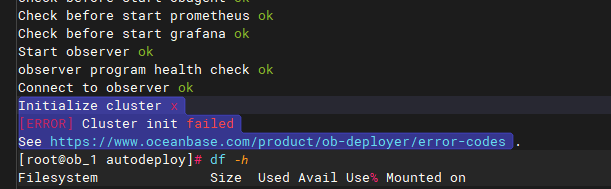
问题现象
使用 OBD 部署 OceanBase 数据库 V4.0.0 时初始化失败,报错:
[ERROR] Cluster init failed。查看 observer.log 日志出现fail to send rpc(tmp_ret=-4122字段。
可能原因
现场防火墙做了限制,导致 rpc 无法互相通信。
解决方案
关闭防火墙。
问题现象
使用 OBD 部署 OceanBase 数据库 V3.1.4 失败,报错:
Cluster bootstrap x。可能原因
可能因为 IP 检测失败。
解决方案
示例中是双网卡环境导致,改成静态固定 IP,将网卡文件 BOOTPROTO=dhcp 改成 static 后重启网络解决。

问题现象
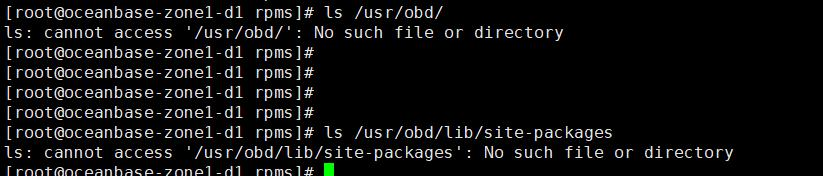
在 pymysql 模块已安装的情况下,使用 OBD V1.6.0 安装 OceanBase V4.0.0 集群的时候提示缺少 pymysql 模块:
ModuleNotFoundError:No module name 'pymysql'。

可能原因
示例中是启动用户不对,直接使用 root 即可,不要切换用户再 sudo,并且看报错缺少 /usr/obd/lib/site-packages 目录应该是 OBD 安装有问题,可以重新安装 OBD,现场通过创建目录拷贝方式最终也能解决。
解决方案
安装时不要使用 sudo 方式,安装使用的是当前用户进行的,创建缺少的 /usr/obd/lib/site-packages 目录,并把 python 模块拷贝进去。
问题现象
使用 OBD 部署 OceanBase 数据库时部署卡在 Remote oceanbase-ce* repository install 阶段。
可能原因
此处会涉及是拉包和传包过程,涉及基础命令,如果非公网是无法使用远程仓库的,如果磁盘可使用空间不足,也无法下载成功。
解决方案
具体需根据 OBD 日志分析,目前已知有如下可能。
- 本机缺少 rsync 命令:可执行
yum install -y rsync命令安装 rsync 命令。- sftp-server 不一致:/etc/ssh/sshd_config 配置和本机 sftp-server 路径保持一致,并重启 sshd 服务。
- 非公网环境,使用了在线安装方式:执行
obd mirror disable remote命令关闭远程仓库拉取安装包,采用离线安装。- 本地磁盘满:下载包较大,磁盘满下载将失败。

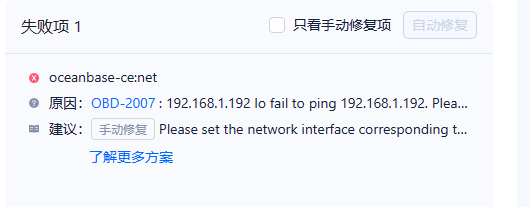
问题现象
使用 OBD V2.1.0 白屏部署,报错 ping 不通:OBD-2007:xx.xx.xx.xx lo fail to ping xx.xx.xx.xx. Please check configuration
devname
可能原因
部署时默认使用 lo 网卡,对应 IP 是本地 127.0.0.1。后续版本会考虑优化。
解决方案
返回
集群配置页面,在更多配置中将devname设置为自定义,填写 IP 对应的网卡名称即可。
OBD 使用问题 #
问题现象
使用 OBD V1.5.0 执行
obd cluster display xx命令时报错ERROR Another app is currently holding the obd lock。可能原因
有其他进程在使用 OBD,OBD 不支持多进程同时操作。
解决方案
确认是否有未结束的 OBD 其他操作,或者有人也在调用 OBD。
问题现象
连接 OceanBase 数据库并执行命令修改完密码,使用 OBProxy 登录数据库报错
ERROR 2013 (HY000): Lost connection to MySQL server at 'reading authorization packet'。可能原因
这个报错基本是密码不一致导致,后台修改密码不会同步到 OBD 配置文件中,导致无法使用 OBD 配置中的密码登录。
解决方案
后台登录数据库还原成 OBD 配置中的密码,再通过
obd cluster edit-config命令编辑配置文件修改密码,保存后执行obd cluster reload重载集群。
OceanBase 数据库使用问题 #
问题现象
手动部署 OceanBase 数据库 V3.1.3,初始化 alter system bootstrap 报错
ERROR 4015 (HY000): System error。可能原因
资源不足,官方要求最小2.5个核心。
解决方案
调大虚拟机 CPU 核数。
问题现象
使用 OceanBase 数据库 4.x 版本新导入的数据时,做 count 查询特别慢?
可能原因
- OceanBase 数据库 4.x 版本支持自动收集统计信息,如果还未触发自动收集统计,需要手动收集统计。
- 数据量大和数据场景复杂的时候,需要手动触发合并会重整数据,加快查询效率。
- 查询如果非单纯 count 表,且租户资源不足扩展时,count 性能就会很慢,需要增大 ob_query_timeout 参数防止查询超时中断。
解决方案
- 手动收集统计信息
- 触发转储合并
- 增加 ob_query_timeout 超时参数
问题现象
OceanBase 数据库 V4.1 创建租户阶段,创建资源时报错
[1235] [0A000]: (conn=3221487627) unit MEMORY_SIZE less than __min_full_resource_pool_memory not supported。·可能原因
该报错主要是设置的 memory_limit 比 __min_full_resource_pool_memory 小导致,__min_full_resource_pool_memory 在 4.x 版本默认是 2G,3.x 版本默认是 5G。
解决方案
如果 MEMORY_SIZE 设置太小,建议是增大资源单元 unit 的 MEMORY_SIZE 参数大小,命令如下。
alter resource unit your_unit_name MEMORY_SIZE='2G';如果 MEMORY_SIZE 无法再增大了,可以降低最小资源池参数限制 __min_full_resource_pool_memory。可参考示例查看和修改该隐藏参数。
-- 查看 SELECT * FROM oceanbase.__all_virtual_sys_parameter_stat WHERE name='__min_full_resource_pool_memory'; -- 修改,示例中 2147483648 为 2G alter system __min_full_resource_pool_memory=2147483648;
问题现象
OceanBase 数据库 V4.0 中使用 select outfile 语法报错权限问题。
obclient [jydb]> select * into outfile ‘/tmp/a.csv’ from a; ERROR 1227 (42501): Access denied可能原因
导出是到本地位置,OBProxy 代理不是本地。
解决方案
通过直连 OBServer 节点连接集群,不能通过 OBProxy 代理连接集群
问题现象
OceanBase 数据库 V4.0 中插入 1W 条数据,报错
1203 (42000): Too many sessions。可能原因
连接池需要程序设置回收。OBProxy 自身的故障或者因流量上升,OBProxy 线程用满(报错信息类似 too many sessions)。
解决方案
应用层使用未配置连接池回收时,可参考官网 OceanBase 数据库文档 ODP 线程满 增加 proxy 服务线程数 client_max_connections 参数。
OBProxy 自身故障可参考官网 Oceanbase 数据库文档 ODP 端故障。
问题现象
测试环境,内存有限,日志报 1001 租户内存不足
WARN [COMMON] try_flush_washable_mb (ob_kvcache_store.cpp:630) [52886][T1001_ReplaySrv][T1001][Y0-0000000000000000-0-0] [lt=4] can not find enough memory block to wash(ret=-4273, size_washed=0, size_need_washed=2097152)。可能原因
OceanBase 数据库 V4.0 引入了用户的 meta 租户概念,其规格配置不支持用户独立设置,具体的规则详见官网 OceanBase 数据库文档 租户的资源管理。
解决方案
可以通过调整 1001 租户的规格来自动调整对应 meta 租户的规格。
问题现象
集群中有三个 Zone,停止 Zone 操作失败
ERROR 4660 (HY000): cannot stop server or stop zone in multiple zones。可能原因
停止 Zone 时需要确保多数派副本均在线,否则操作会失败。
解决方案
环境是三个 Zone,停止一个 Zone 后,再停止一个是不允许的。
问题现象
OceanBase 数据库 V3.1.4 新建租户后,使用租户信息无法登录集群,报错
ERROR 1227 (42501): Access denied。可能原因
创建租户时默认密码为空,如果不能登录,一般是未设置白名单,导致无访问权限。
解决方案
登录系统租户(root@sys)为新创建的租户设置白名单。
ALTER TENANT xxx SET VARIABLES ob_tcp_invited_nodes='%';使用 -h127.0.0.1 登录业务租户,执行命令为本租户设置白名单。
SET GLOBAL ob_tcp_invited_nodes='%';
问题现象
字段为外键时插入数据报错
1235 - Not supported feature or function。可能原因
使用的是 sys 租户,sys租户仅做集群管理使用,不可当做业务租户。普通租户下字段为外键时可以正常插入。
解决方案
新建普通租户进行业务使用。
问题现象
集群无法连接,observer 进程挂掉,报错
worker cnt larger than max cnt。可能原因
基本为租户 CPU 资源不足够导致。
解决方案
调大 sys_cpu_limit_trigger 参数,使其大于 16,或者更大。
问题现象
load data 导入数据报错
ERROR 1227 (42501): Access denied。可能原因
访问数据文件无权限导致。
解决方案
将导入的数据文件放到启动 OceanBase 数据库的用户权限下执行,或者执行如下命令。
set global secure_file_priv = '/tmp’;
问题现象
在 Anolis8.6 机器下,部署 OceanBase 数据库 V3.1.4 时,eth0 网卡 ping 服务器正常,但部署报错 ping 失败:eth0 fail to ping xxx.xxx.xxx.xxx. Please check configuration
devname。可能原因
兼容性问题,后续版本修复。
解决方案
执行
chmod u+s /usr/sbin/ping命令。
问题现象
升级 OceanBase 数据库 V3.1.0 至 V3.1.4 失败,报错:
fail to get upgrade graph: ‘NoneType’ object has no attribute ‘version’。可能原因
OceanBase 数据库 V3.1.0 不支持本地升级,只能做数据迁移这种逻辑升级。
解决方案
重新搭建一套 OceanBase 数据库 V3.1.4 环境,通过 OMS 进行数据迁移。
问题现象
OceanBase 数据库 V3.1.4 中使用业务租户修改 lower_case_table_names 参数报错
Variable 'lower_case_table_names'is a read only variable。可能原因
MySQL 的只读变量在 MySQL 里即使是 root 也不能修改,需要拥有主机访问权限的人在外部修改配置文件后重启实例生效。OceanBase 数据库的 MySQL 租户是逻辑实例,没有独立进程,不存在重启操作。所以需使用有 sys 租户权限的超级管理员去修改租户的全局参数变量。
解决方案
使用系统租户 root@sys 操作。
问题现象
OceanBase 数据库 V3.1.4 中一次性导入大批数据报错租户内存不足
ERROR: No memory or reach tenant memory limit。可能原因
有如下两种原因。
- 系统租户本身作为系统管理者,资源有限,不适合业务使用。
- 磁盘写满,无法触发转储合并,租户内存会写满。
解决方案
根据不同原因有如下几种解决方案。
- 不能使用系统租户 root@sys 当业务租户使用。
- datafile_size 不能太小,防止租户的磁盘被写满。
- 通过参数调优,可以降低内存写满风险
- 租户内存阈值 memstore_limit_percentage 调大。
- 触发版本冻结的阈值 freeze_trigger_percentage 调小。
- MemStore 写入限速阈值 writing_throttling_trigger_percentage 设置 70。
问题现象
OBClient(2.x 版本)通过 OBProxy 连接 OceanBase 数据库(V4.0.0)proxysys 租户时报错
ERROR 2027 (HY000): received malformed packet,但是使用 MySQL 客户端连接正常。可能原因
OBClient 2.x 版本使用 root@proxysys 用户连接到 OceanBase 数据库之后,会发送 SQL 语句查询 version,OBProxy 会直接回复 EOF 包,这个包在 OBClient 1.x 版本时是会被忽略,在 OBClient 2.x 版本时会解析异常。
解决方案
可暂时使用 MySQL 客户端,该问题下个迭代修复。
问题现象
OceanBase 数据库 V4.0.0 中导入表的时候总是报
ERROR 4263 (HY000): Minor freeze not allowed now,且无法 truncate 表数据。查看日志显示如下。WARN [STORAGE.BLKMGR] alloc_block (ob_block_manager.cpp:305) [9021][T1_MINI_MERGE][T1][YB42C0A81FCA-0005EC7D0FFFD8D6-0-0] [lt=22] Failed to alloc block from io device(ret=-4184) WARN [STORAGE] alloc_block (ob_macro_block_writer.cpp:1132) [9021][T1_MINI_MERGE][T1][YB42C0A81FCA-0005EC7D0FFFD8D6-0-0] [lt=4] Fail to pre-alloc block for new macro block(ret=-4184, current_index=0, current_macro_seq=0)可能原因
Minor freeze not allowed now 指的是无法进行转储,原因一般有:
- 租户分配磁盘空间占满,内存的数据无法转储。
- 使用了系统租户当业务租户使用,系统租户资源较少,转储性能跟不上。
- 使用了业务租户,但该租户的内存资源较少,转储性能跟不上。
解决方案
增大对应租户的磁盘资源,命令如下。
alter resource unit xxx datafile_size='xxG'
问题现象
部署 OceanBase 数据库 V4.0.0 时报错
[ERROR] OBD-1006: Failed to connect to oceanbase-ce。查看 observer.log 日志显示ERROR [CLOG] resize (ob_server_log_block_mgr.cpp:183) [2790][][T0][Y0-0000000000000000-0-0] [lt=5] The size of reserved disp space need greater than 1GB!!!(ret=-4007。可能原因
log_disk_size 用于设置 Redo 日志磁盘的大小,不能小于 1G 的限制,默认为分配内存的 3~4 倍。
解决方案
配置文件中调大 log_disk_size 参数。
问题现象
单机 demo 部署 OceanBase 数据库 V4.0.0 ,通过 OBProxy 连接数据库时经常出现断连现象,但是通过 OBServer 直连却没有问题。报错信息如下。
ERROR 2013 (HY000): Lost connection to MySQL server during query ERROR 2006 (HY000): MySQL server has gone away No connection. Trying to reconnect…可能原因
现在 demo 模式中 OBProxy 给的内存比较少(200M),可能有触发内存超限重启的问题,后续版本会优化。
解决方案
执行如下命令调大 proxy_mem_limited 参数为 500M 或 1G。
alter proxyconfig set proxy_mem_limited ='1G';
问题现象
通过 OBD 单机部署 OceanBase 数据库 V3.1.4 后启动失败,通过 OBProxy 连接报错
ERROR 2013 (HY000): Lost connection to MySQL server at 'reading authorization packet', system error: 0,日志报错如下。ERROR [SERVER.OMT] alloc (ob_worker_pool.cpp:93) [24864][454][Y0-0000000000000000] [lt=22] [dc=0] worker cnt larger than max cnt(worker_cnt_=256, max_cnt_=256)可能原因
OceanBase 数据库最低以 cpu_count 16 启动,如果修改过该参数可能导致无法启动。
解决方案
执行
obd cluster edit-config编辑配置文件,调大 cpu_count 配置项,保存修改后根据黑屏输出执行对应命令重启即可。
问题现象
导入数据到 OceanBase 数据库 V4.0.0 期间出现切主报错信息
ERROR [ELECT] leader_revoke (ob_election.cpp:2151) [42767][1849][Y0-0000000000000000] [lt=13] [dc=0] leader_revoke, please attention!(revoke reason=“clog sliding_window timeout”可能原因
Leader 同步 Clog 超时导致切主。
解决方案
可以尝试调小客户端压力,或者调大 _ob_clog_timeout_to_force_switch_leader,这是日志同步超时配置项,可以通过 oceanbase.__all_sys_parameter 表查看,默认值为 10 秒,可适当调大,影响是 leader 异常时,相应的 RTO 也会变长。
问题现象
OceanBase 数据库 V3.1.0 申请不到内存,合并超时,转储卡住。日志报错:
Fail to alloc data block, (ret=-9202)。可能原因
有如下两种可能原因。
- 可能是磁盘被占满,可以通过
df -h查看。- 可能是设置的 datafile 使用完了,可以通过查询 __all_virtual_disk_stat 查看 OceanBase 数据库整体磁盘占用信息。
解决方案
可通过扩容解决,或者增大 datafile_size / datafile_disk_percentage 配置。
问题现象
OceanBase 数据库 V3.1.4 执行合并报错:
ERROR 4179 (HY000): Operation not allowed now,rootserver 日志报错:enable_major_freeze is off, refuse to to major_freeze。可能原因
enable_major_freeze 默认是开启的,测试环境修改了参数,导致无法手动触发合并。
解决方案
执行
alter system set enable_major_freeze='true';打开合并参数。
问题现象
OceanBase 数据库 V4.1 中 sys 租户设置数据备份路径报错。
- 执行 SQL:
ALTER SYSTEM SET data_backup_dest=‘file:///data/bak’;。- 报错:
ERROR 1235 (0A000): Not supported feature or function。- 日志信息:
WARN log_user_error_inner (ob_table_modify_op.cpp:1042) [7800][EvtHisUpdTask][T1][YB42ACAC1F54-0005F645ABA8855E-0-0] [lt=18] Data too long for column ‘value2’ at row 1。可能原因
OceanBase 数据库 4.x 版本为租户级别备份,且 sys 租户不能为其自身备份,sys 租户登录操作的话,需要指定备份的租户,其中 log_archieve_dest/data_backup_dest 也只能为业务租户备份设置。
解决方案
设置时指定为业务租户:
ALTER SYSTEM SET data_backup_dest=‘file:///data/bak/’ TEANT = $your_tenant_name;。
问题现象
OceanBase 数据库 V4.1 后台设置日志归档备份路径报错。
- 执行 SQL:
ALTERSYSTEMSET LOG_ARCHIVE_DEST='LOCATION=file:///data/bak' TENANT = fund;。- 报错:
ERROR 9081 (HY000): the content of the format file at the destination does notmatch。可能原因
OceanBase 数据库 4.x 版本,日志备份目录 log_archive_dest 和数据目录 data_backup_dest 不能在同级目录下。因为每一个路径下都有一个 format 校验文件,该文件记录该路径的一些相关属性,设计上不允许备份目录相同。
解决方案
将日志备份目录和数据目录设置到不同目录层级下,例如:
ALTER SYSTEM SET data_backup_dest='file:///data/bak/logdir';。
问题现象
OCP 备份和手动发起 ALTER SYSTEM ARCHIVELOG 命令报错
ERROR 1235 (0A000): start log archive backup when not STOP is not supported可能原因
日志备份进程仍在,不能重复执行备份。
解决方案
如果是初次全量备份,可以关停备份并清理备份任务和进程,重新发起。
--关闭日志备份 ALTER SYSTEM NOARCHIVELOG; --强制取消所有备份任务(备份目录会重置) ALTER SYSTEM CANCEL ALL BACKUP FORCE; --查看备份路径 SHOW PARAMETERS LIKE 'backup_dest' --修改备份目录 ALTER SYSTEM SET backup_dest='file:///data/obbackup'; --启动日志备份 ALTER SYSTEM ARCHIVELOG
问题现象
OceanBase 数据库 V3.1.4 启动日志备份后,很快就显示断流 interrupted。查看日志显示
log archive status is interrupted, need manual process(sys_info={status:{tenant_id:1, copy_id:0, start_ts:1671070878595931, checkpoint_ts:1671070878595931, status:5, incarnation:1, round:3, status_str:“INTERRUPTED”, is_mark_deleted:false, is_mount_file_created:true, compatible:1, backup_piece_id:0, start_piece_id:0}, backup_dest:“file:///home/nfs_server/backup”})。可能原因
有如下两种可能原因。
- nfs客户端配置错误。
- nfs服务器目录权限不够。
解决方案
根据以上原因,有如下两种解决办法。
- OceanBase 数据库为 NFS 客户端,需要所有 OBServer 节点本地创建备份目录挂载到服务端的 NFS 地址。
- 将 NFS 服务器上 backup 目录修改属组 nfsnobody:nfsnobody,或者 777 权限。
问题现象
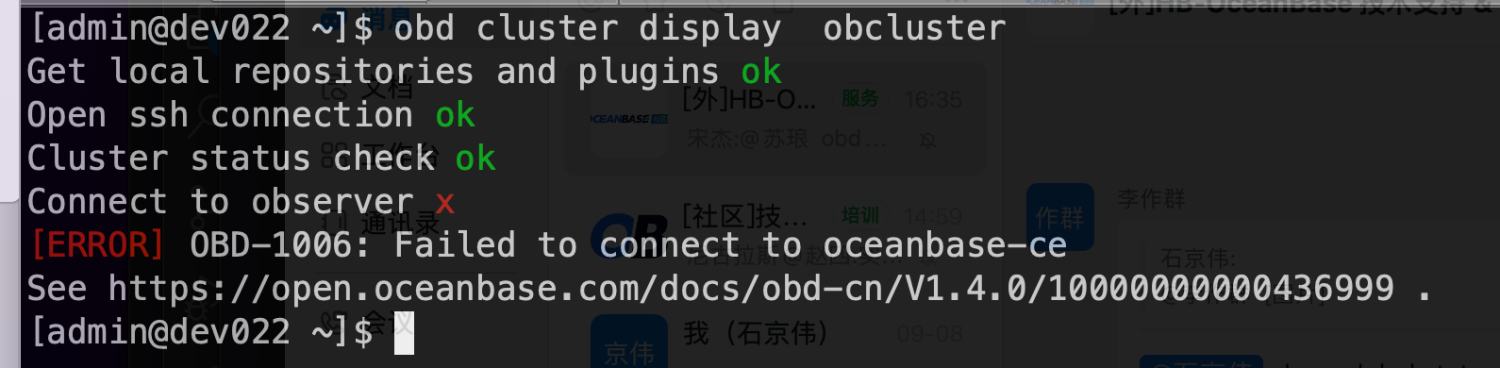
用 OBD 管理集群时报错
OBD-1006: Failed to connect to oceanbase-ce,实际集群状态正常,OBD 日志报错密码不正确Access denied for user。可能原因
用户未通过 OBD 方式修改密码,而是直接登录数据库修改,但 OBD 配置文件不会同步修改,导致密码配置不一致,且当前情况下因为密码已经不一致,无法再通过 OBD 修改密码。
解决方案
登录数据库设置系统租户密码和 OBD 配置文件中
root_password配置项保持一致,此时可以成功通过 OBD 管理集群。若仍想修改密码,可执行obd cluster edit-config命令编辑配置文件,修改root_password配置项为想要修改的密码。
问题现象
OceanBase 数据库 V3.1.4 日常使用抛出报错
ERROR 4654 (HY000) at line 1: location leader not exist。 查看日志出现leader revoke,please attention!(revoke reason="clog sliding_window_timeout")。
可能原因
看第一个日志是 leader 被 revoke,observer.log 是超时了,有可能是与其他节点 NTP 时钟同步有较大差值。
解决方案
检查节点间的时差是否超出 50ms,或者执行如下命令调大系统参数。
alter system set _ob_clog_timeout_to_force_switch_leader ='10s';

问题现象
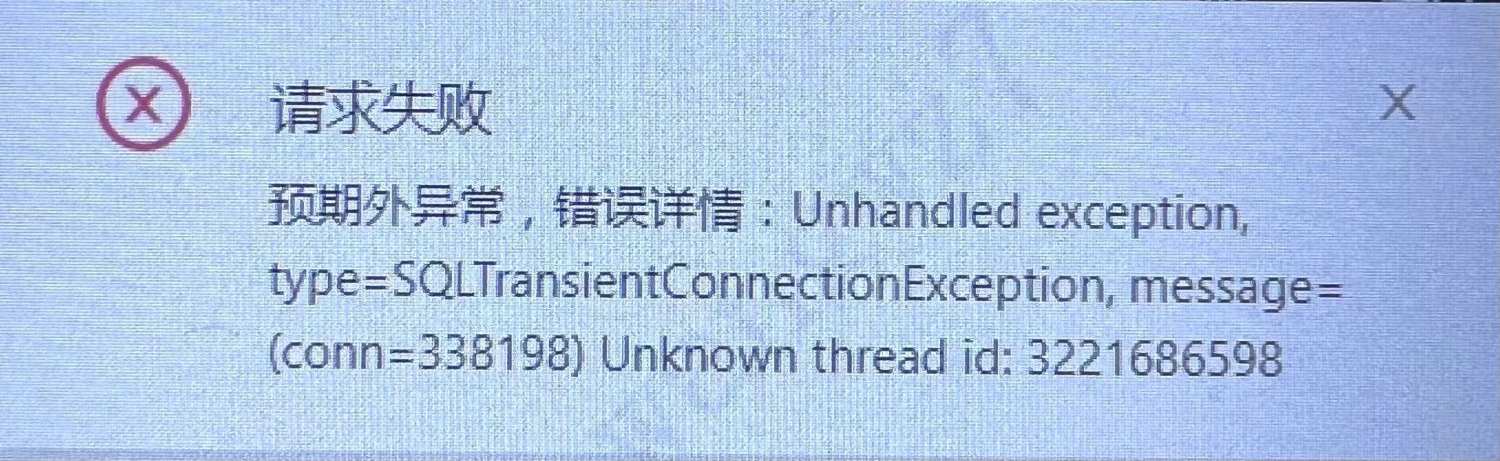
ODC 上 执行 SQL 报错
Unkown thread id。可能原因
unknow thread id 是因为在 JDBC 代码执行 SQL 时,设置了 ob_query_timeout,超时后驱动就会执行
kill query connectionId命令将超时执行的 SQL 取消掉。但是这个命令在存在多个 OBProxy 时,可能会发给其他的 OBProxy,就会报错 unknow thread id。解决方案
增大超时参数 ob_query_timeout,同时也建议增大事务参数 ob_trx_timeout、ob_trx_idle_timeout。
问题现象
OceanBase 数据库 V3.1.4 动修改 observer.config.bin 文件后启动失败,报错
check data checksum failed(ret=-4103)。可能原因
首先不支持直接手动修改该二进制文件,该文件配置参数是通过 alter system 方式持久化此处的,可以通过
./bin/observer -o 参数=参数值的方式启动,启动成功后也会持久化到该配置,当然。解决方案
etc2 和 etc3 下有备份文件,该配置文件加上 history 一共有六份,可以 cp etc2/observer.conf.bin etc/observer.config.bin 恢复配置。
find /home/admin/oceanbase |grep "observer.conf" /home/admin/oceanbase/etc3/observer.conf.bin /home/admin/oceanbase/etc3/observer.conf.bin.history /home/admin/oceanbase/etc2/observer.conf.bin /home/admin/oceanbase/etc2/observer.conf.bin.history /home/admin/oceanbase/etc/observer.config.bin /home/admin/oceanbase/etc/observer.config.bin.history

问题现象
OceanBase 数据库 V4.0.0 使用 MySQL 驱动,连接报错
java.lang.ClassNotFoundException: com.mysql.jdbc.Driver。可能原因
MySQL 驱动写 MySQL 的信息格式为
jdbc:mysql,如果是 OceanBase 驱动需要写 OceanBase 信息格式为jdbc:oceanbase。解决方案
修改驱动连接为
jdbc:mysql。

问题现象
springboot 项目使用 OceanBase 数据库 V4.0.0,数据库中字段是 datetime 格式,用 bean 接收 SQL 查询的结果,bean 中使用 string 来接收,出现
2022-12-08 12:23:56.0,预期结果是2022-12-08 12:23:56。解决方案
对于 OceanBase 数据库的 datatime 格式,建议使用 Date 的数据类型接收。如果想要用 String 接收 OceanBase 数据库的时间类型,建议尝试将数据库改为 timestamp 格式。
问题现象
OceanBase 数据库 V4.0.0 在给日期类型 datetime 的字段按年分区时报错
ERROR 1564:This partition function is not allowed。可能原因
原生 MySQL 也如此表现,报错符合预期,Hash 分区键的表达式必须返回 INT 类型,left 截取方式返回的是字符串类型。
解决方案
可以按如下函数语法获取年/月。
- PARTITION BY RANGE( YEAR(dt) )
- SUBPARTITION BY HASH( MONTH(dt) )

问题现象
OceanBase 数据库 V4.0.0 在 write only 场景时,磁盘读在一个较高的频率,纯写场景为什么会有这个高的读操作?
可能原因
OceanBase 数据库的存储整体是一个 LSM 架构,从上到下是 MemTable,Minor SSTable,Major SSTable,数据从 MemTable 到 SSTable 会写盘,从 Minor 到 Minor/Major 会读盘 + 写盘,Minor SSTable 累积一定数量后也会触发合并,合并需要重排列,需要读+写磁盘。
解决方案
符合预期,无需解决。
OCP 部署问题 #
问题现象
部署 OCP V3.3.0 时报错
1146(42S02):Table‘meta_database.compute_vpc’ doesn’t exist。可能原因
这是 OCP V3.3.0 的已知 bug 问题,已发布 bp 版本中已经修复。
解决方案
可以先在 ocp meta 租户的库中确认是否已经存在 compute_vpc 表,如果存在,把其他的表删除,仅保留 compute_vpc,之后重新初始化 OCP。
问题现象
部署 OCP V3.3.0 时报错
resource not enough:memory(Avail:1.6G,Need:8.0G)。可能原因
memory_limit 默认使用物理总内存 80%,但如果可用内存不足,会出现创建租户时申请不到资源。
解决方案
可在 custom_config 模块中将 memory_limit 设置为服务器可用内存范围以内(可执行
free -g命令查询内存)。
问题现象
部署 OCP V4.0.0 时报错预检测失败:
ocp precheck failed。可能原因
预检测会检查服务器硬件资源是否符合生产环境标准,如果不通过会报此错误,测试环境建议关闭预检测功能。
解决方案
关闭预检参数,即将 precheck_ignore 设置为 true。

问题现象
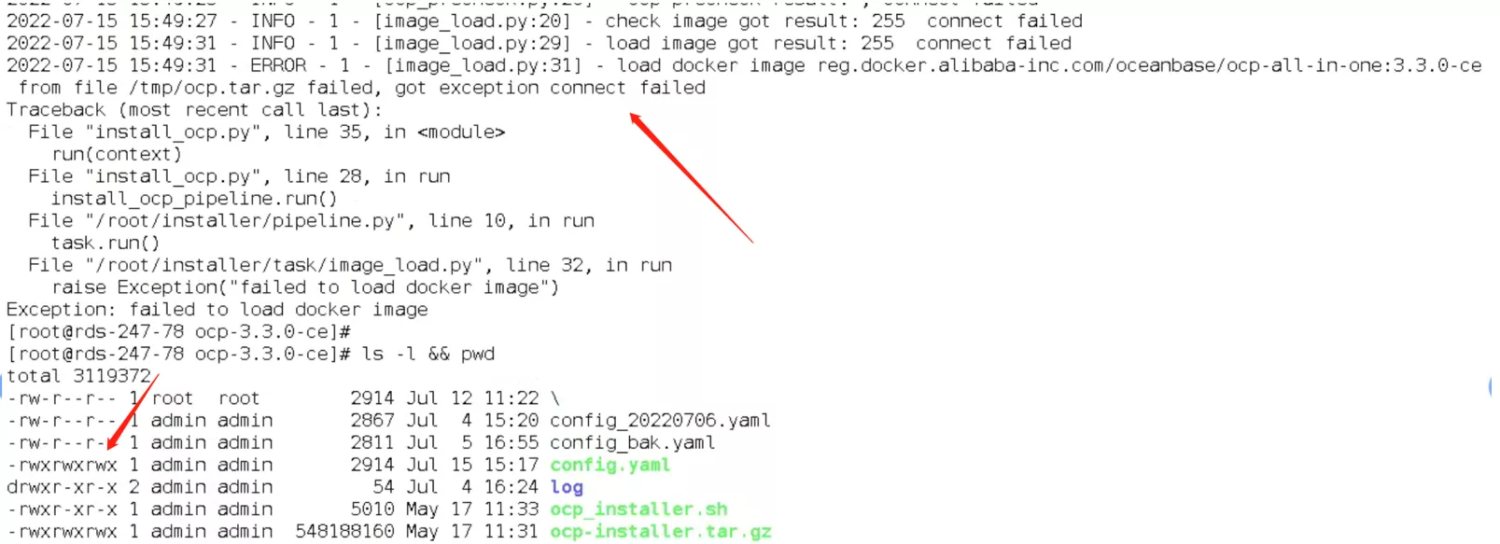
部署 OCP V3.3.0 时加载 Docker 镜像流程失败,报错:
failed to load docker image。可能原因
安装的时候是当成远程主机,需要涉及节点之间 ssh 互信。
解决方案
检查 ssh 互信是否正常。
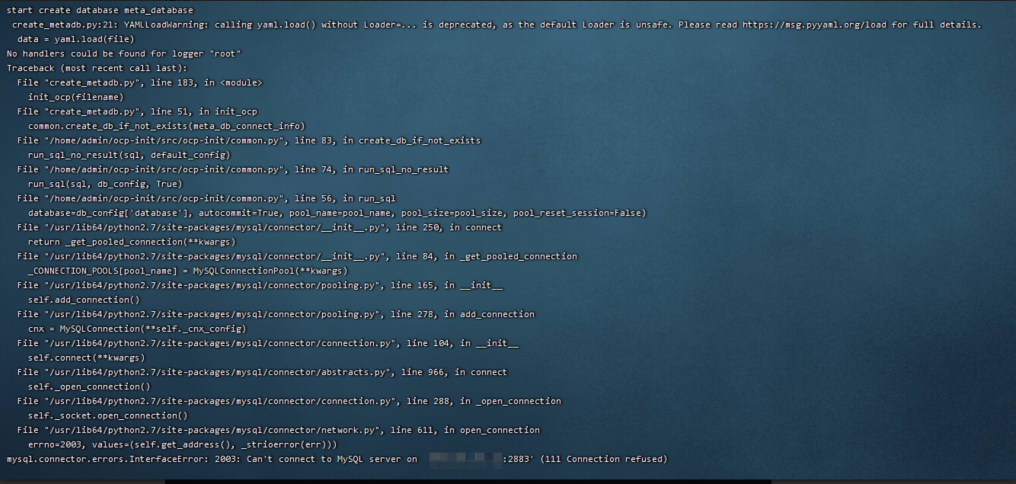
问题现象
部署 OCP V3.3.0 是报错无法连接到 metadb:
2003:Can't connect to MySQL on 'xx.xx.xx.xx' (111 Connection refused)。可能原因
create_metadb_cluster 参数默认为 false,会使用配置中 ob_cluster 模块信息当 metadb,可能是实际操作中 metadb 不存在。
解决方案
配置文件 create_metadb_cluster 设置为 true,默认安装个 metadb 数据库。
问题现象
OCP V4.0.0 部署中报错
PermissionError: [Errno 13] Permission denied: '/root/installer/config.yaml'。可能原因
selinux 会影响程序的访问文件,影响程序的服务程序功能,影响服务所使用的资源,部署前需要关闭。
解决方案
关闭 selinux。

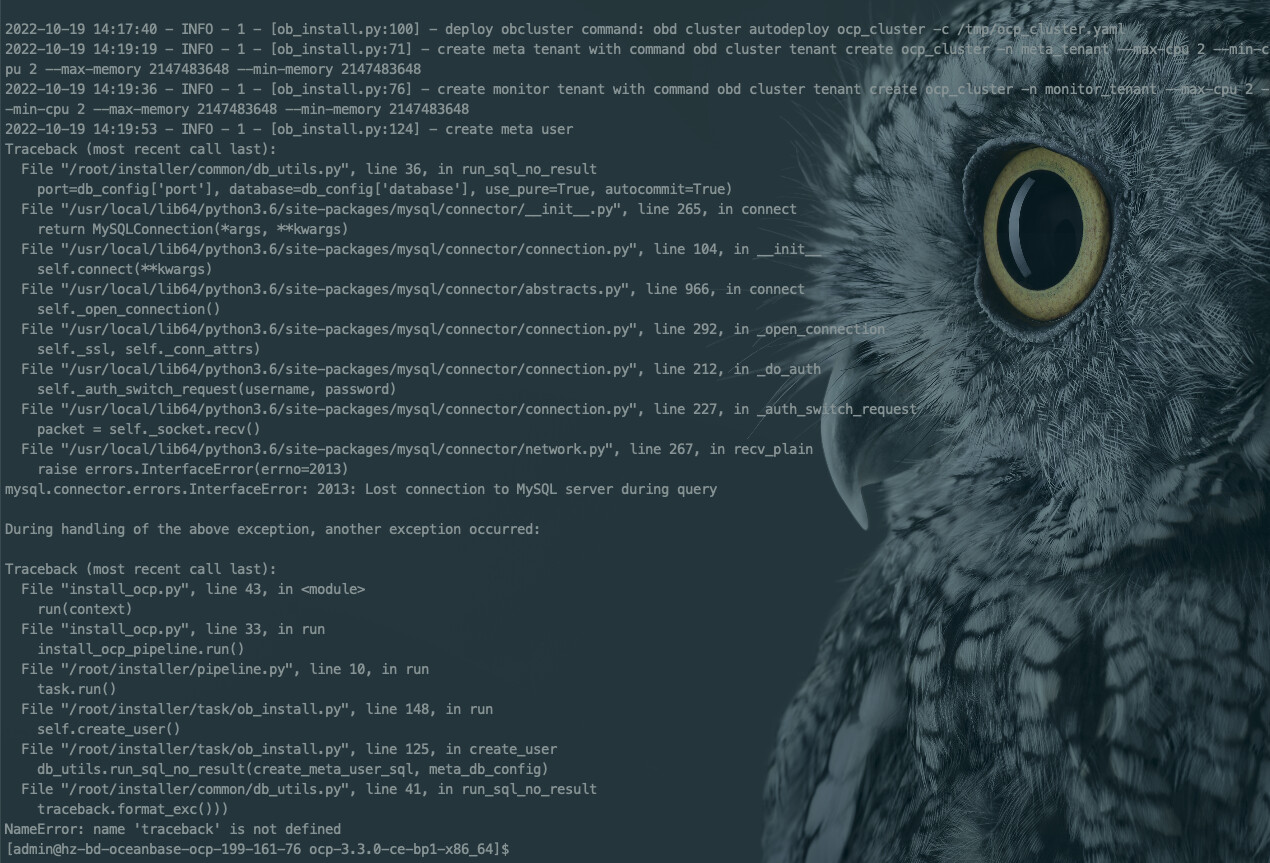
问题现象
OCP V3.3.0 部署过程中,create meta user 阶段报错
NameError: name ‘traceback’ is not defined。可能原因
可能是找不到对应的文件导致,删除重新部署会产生新的文件。
解决方案
检查
/tmp目录下是否有precheck-*.sh文件(-*是当时生成的 uuid),如果有,删除即可。
问题现象
OCP V3.3.0 部署时 metadb 初始化阶段报错
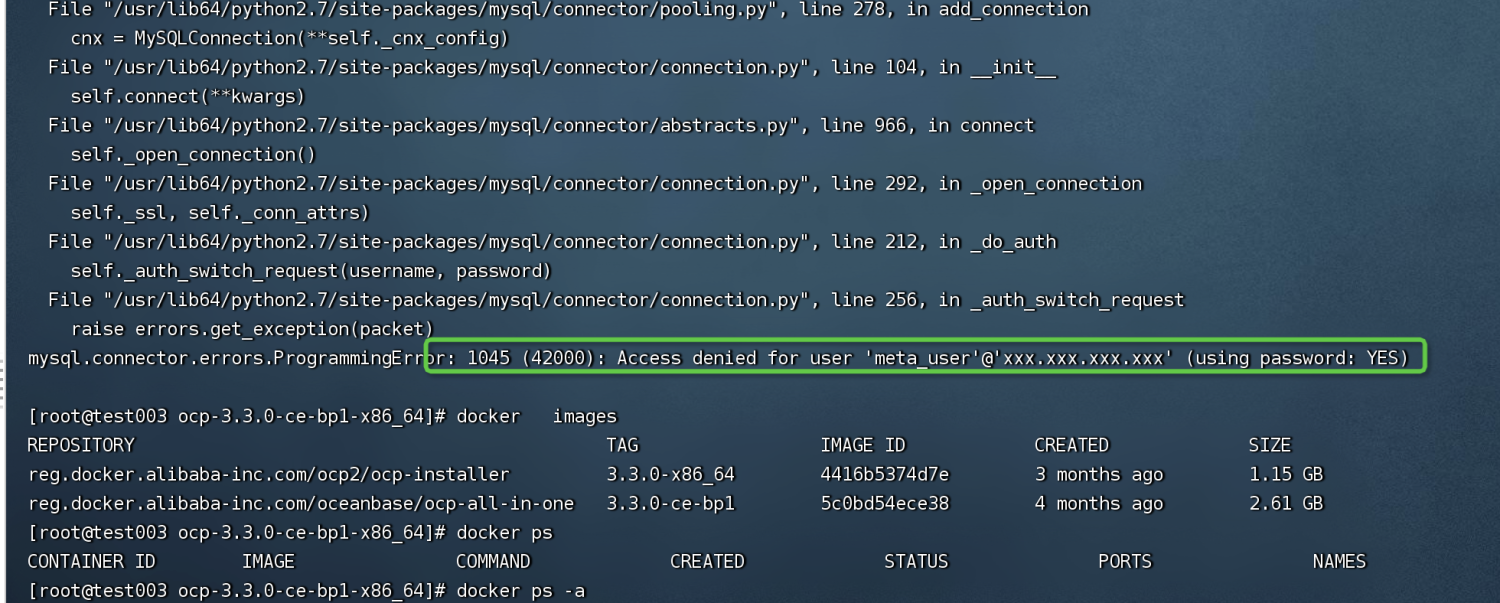
Access denied for user 'meta_user'@'xxx.xxx.xxx.xxx。可能原因
示例中仅仅只有 5G 内存,此处报错不一定是连接密码问题,可能是启动容器失败,还未到连接抛出异常。
解决方案
若是由内存不足导致,可增加内存。
问题现象
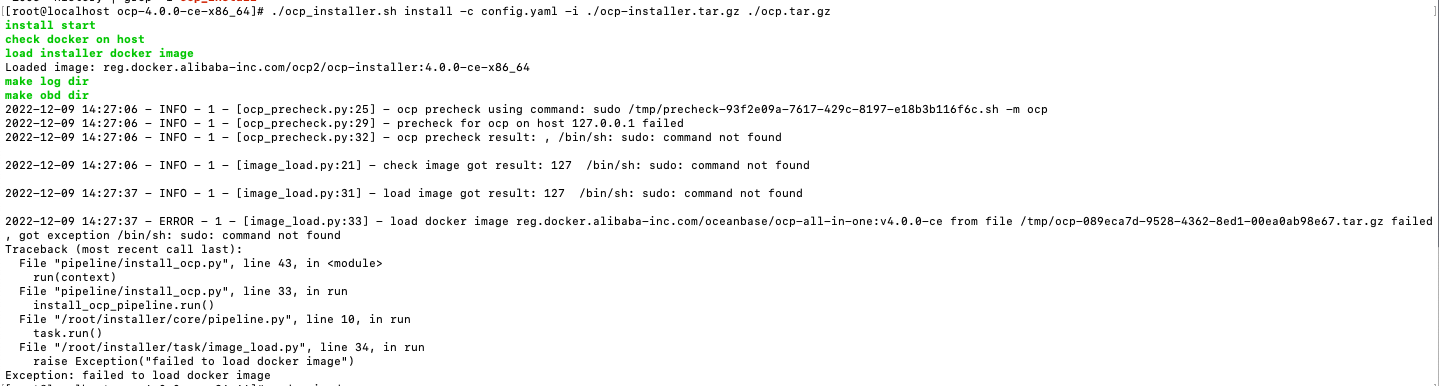
OCP V4.0.0 安装过程中报错
/bin/sh: sudo: command not found,最终导致 failed to load docker image。可能原因
暂未复现,用户配置环境问题影响较大。
解决方案
可在 OCP 的 config.yaml 文件中 ssh 模块配置上密码信息。
OCP 使用问题 #
问题现象
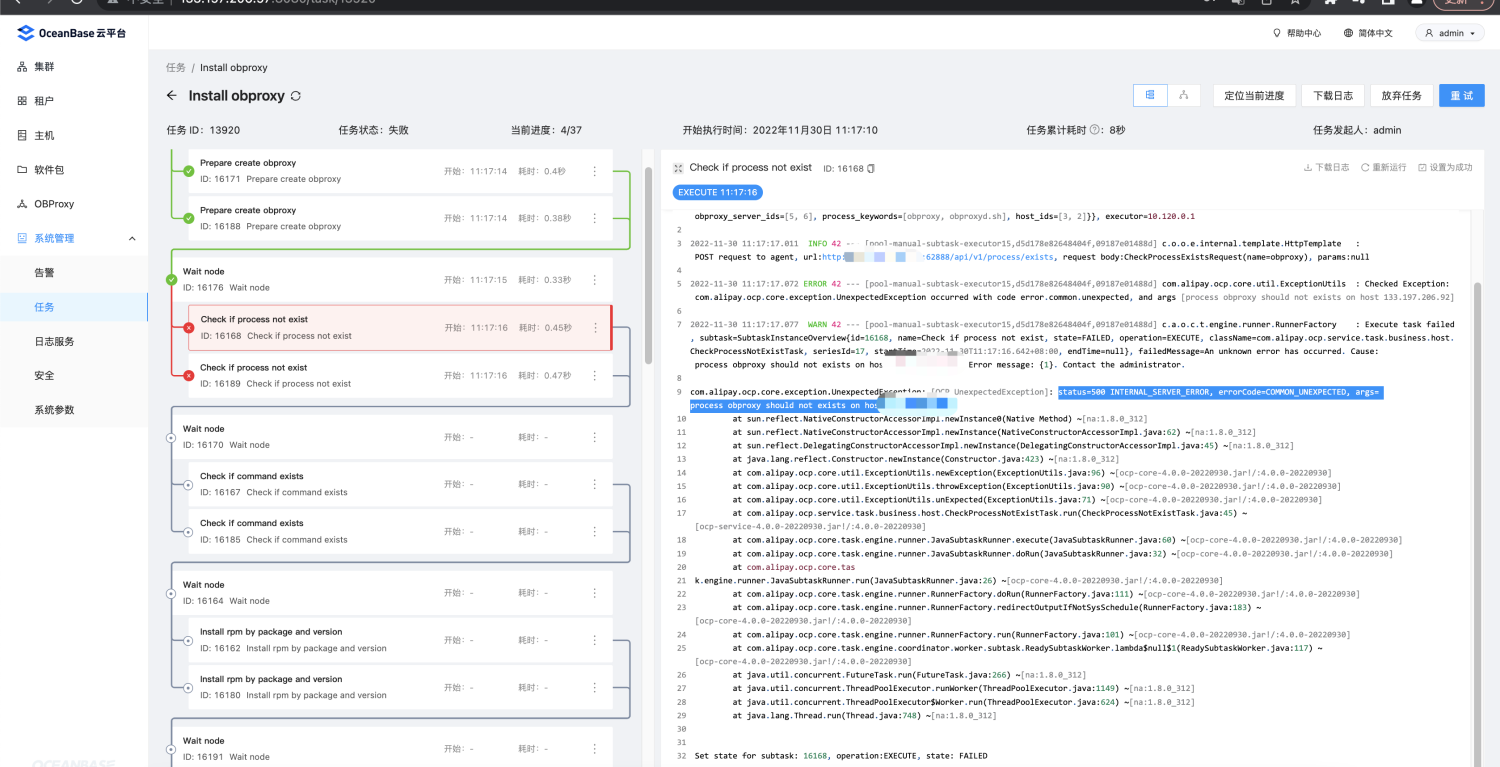
使用 OCP V4.0.0 部署 OBProxy 时,check if process not exit 阶段失败,报错:
status=500 INTERNAL_SERVER_ERROR, errorCode=COMMON_UNEXPECTED, args=process obproxy should not exists on host。可能原因
该节点已存在 OBProxy 服务和进程。
解决方案
更换默认的 2883 端口,或者卸载该节点已经部署的 OBProxy 服务。
问题现象
使用 OCP 接管时报错 observer 进程属于 root,需要使用 admin 账号。
可能原因
OCP 接管限制中,要求 observer 进程启动用户必须是 admin。
解决方案
接管的详细操作可参见 SOP 文档 【SOP 系列 07】如何使用 OCP 接管 OBD 部署的 OceanBase 集群
问题现象
OCP V4.0.0 部署集群时卡在 Bootstrap ob 阶段,日志提示
try adjust config ‘memory_limit’ or ‘system_memory’。可能原因
system_memory 默认是 30G,memory_limit_percentage 默认是占用 80% 的物理内存,如果不指定这两个参数配置信息,小规格服务器配置可能出现申请不到内存问题。
解决方案
调小 memory_limit 和 system_memory 参数。
问题现象
OCP 部署 OceanBase V3.1.4 集群时 bootstrap ob 失败,查看日志显示
ERROR [CLOG] update_free_quota (ob_log_file_pool.cpp:465) [77084][0][Y0-0000000000000000] [lt=3] [dc=0] clog disk is almost full(type_=0, total_size=1888745000960, free_quota=-198549053440, warn_percent(%)=80, limit_percent=95, used_percent(%)=90)。可能原因
OceanBase 数据库中数据文件采用预占用方式,同盘会出现磁盘空间不足问题,生产环境必须分盘,测试环境可降低占用比例。
解决方案
使用 OCP 部署集群时安装路径参数 home_path 、data、redo 采用分盘部署,不要混部到一块盘上,如果是简单测试,可以把 datafile_size 或者 datafile_disk_percentage 调小。
问题现象
使用 OCP V3.3.0 部署 OceanBase 数据库时,Pre check for install ob 阶段异常,报错
ob install pre check failed,maybe from another observer。可能原因
OCP 不支持在已有 observer 进程的集群环境再部署一套 OceanBase 集群。
解决方案
卸载 OBServer 节点上的 observer 进程,或者使用未部署过 OceanBase 数据库的资源环境。
问题现象
使用 OCP V3.3.0 接管 V3.1.4 OceanBase 集群时,使用 proxy 连接 OCP 报错 OBProxy proxyro 用户密码与 OCP 设置不相同。
可能原因
OCP 初始的 proxyro 密码是空,如果 OceanBase 集群中设置了 proxyro 密码,需要 OCP 也保持一致。
解决方案
执行如下命令修改 OCP 中 proxyro 密码。
curl --user admin:aaAA11__ -X POST "<http://xx.xx.xx.xx:8080/api/v2/obproxy/password>" -H "Content-Type:application/json" -d '{"username":"proxyro","password":"*****"}'
--user后需填写 OCP 白屏登录用户:密码,xx.xx.xx.xx:8080为 OCP 地址:端口*****为 OBD 部署配置文件中 observer_sys_password 参数的密码。
问题现象
使用 OCP V4.0.3 接管 OBD 部署的 4.x 版本 OceanBase 数据库时,报错 OBProxy proxyro 用户密码与 OCP 设置不相同。
可能原因
OCP V4.0.3 废弃了 /api/v2/obproxy/password 接口,无法通过接口方式保持两端密码一致。后续版本会优化。
解决方式
可执行
obd cluster edit-config 部署名称命令修改 proxyro_password 和 observer_sys_password 一致为3u^0kCdpE,保存修改后再执行obd cluster reload 部署名称命令即可。
问题现象
OceanBase 数据库 V3.1.4 在业务租户有批量或者手工导数期间,偶然性会有告警
plan cache memory used reach limit。可能原因
如果租户内存设置太小,或者批量导数条数不一致可能出现此类报错。
解决方案
扩容租户内存或执行如下命令调整 ob_plan_cache_percentage 阈值。
show variables like'%ob_plan_cache_percentage%'; set global ob_plan_cache_percentage =10;
问题现象
使用 OCP 接管 OceanBase V4.0.0 集群时报错所在 IDC 与目标 OBServer 的 IDC 不匹配。
可能原因
因为接管前已经人为将节点添加到主机列表中,列表中的 IDC 机房和 Region 地区信息和接管的集群默认信息不一致。
解决方案
主机列表删掉对应的节点信息,重新接管。也可以登录 OceanBase 数据库通过 SQL 修改 IDC 和 Region 信息。
alter system alter zone 'zone1' set idc = 'xx;alter system alter zone 'zone1' set region = 'xx';
问题现象
OCP 上创建的 unit 规格配置不显示。
可能原因
小于 5G 的 Unit 规格在前端展示的时候会被过滤掉。
解决方案
连接 OCP 的 meta 租户,查看该限制的控制参数:
select * from config_properties where key like ‘%small%’ \G。在特殊情况下,比如 demo 演示等非生产环境中,可以将其改为 true,就会取消这个限制,命令如下。UPDATE config_properties SET value='true' WHERE `key` = 'ocp.operation.ob.tenant.allow-small-unit';
问题现象
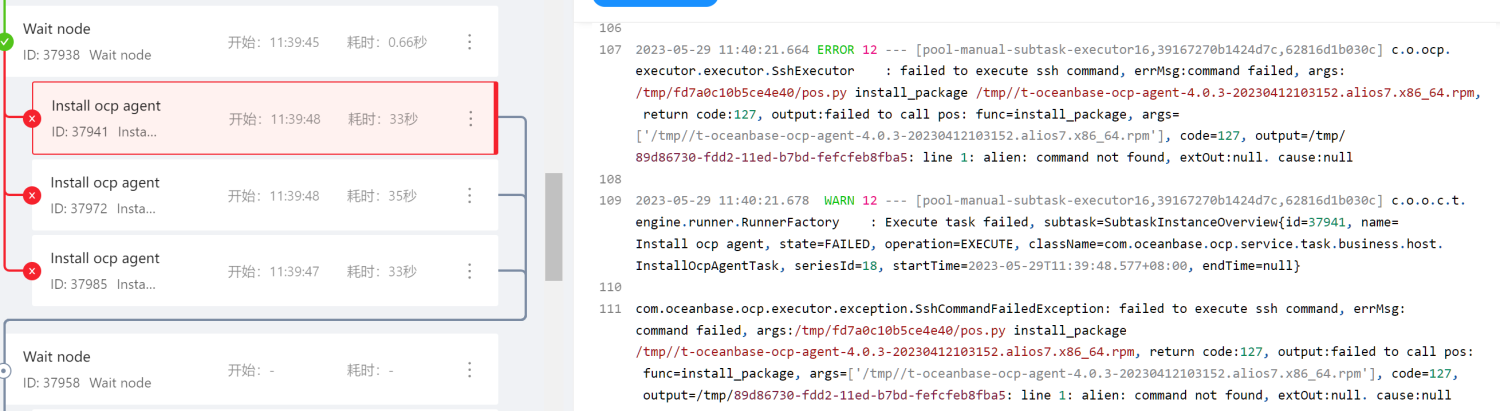
OCP V4.0.3 中添加主机,无法安装 ocp agent 服务。
报错:args:/tmp/8c76f061414e4d6/pos.py uninstall_package ^t-oceanbase-ocp-agent, return code:2, output:failed to call pos: func=uninstall_package, args=[’^t-oceanbase-ocp-agent’], code=2, output=/tmp/a463f6de-fde4-11ed-8e6e-fefcfeb8fb: line 1: unexpected EOF while looking for matching `’’。
可能原因
示例中使用的是 Centos7 系统,安装 ocp-agent 前会做操作系统检查,可能因为 dpkg 命令会错误的判断现场操作系统类型。
解决方案
执行如下命令卸载 dpkg 命令。
rpm -qa|grep dpkg , rpm -e --nodeps $dpkg
问题现象
使用 OCP 部署 OBProxy V4.1 后,使用 OBProxy 连接 OceanBase 数据库报错密码错误,查看 OBProxy 日志显示
fail to get cluster name(ret=-4018)。可能原因
OCP 部署的 OBProxy 虽然关联了 OceanBase 集群,但是 OBProxy 可能关联了多个 OceanBase 集群,需要增加集群名称进行区分。
解决方案
使用 OBProxy 连接 OceanBase 数据库时
-u参数写完整,需带上待连接的 OceanBase 集群名称,即-uroot@sys#集群名称格式。

问题现象
使用 OCP V4.0 添加主机报错,白屏页面显示没有找到指定 OCP Agent 类型的记录。
报错:No route to host (Host unreachable)
可能原因
待添加的主机防火墙开启,安装程序路由不到该节点。
解决方案
关闭待添加主机的防火墙即可。


问题现象
使用 OCP 部署 OceanBase 数据库 V3.1.2,使用 root 用户后台启动 observer 后,再重新使用 admin 用户启动失败。。查看日志报错如下。
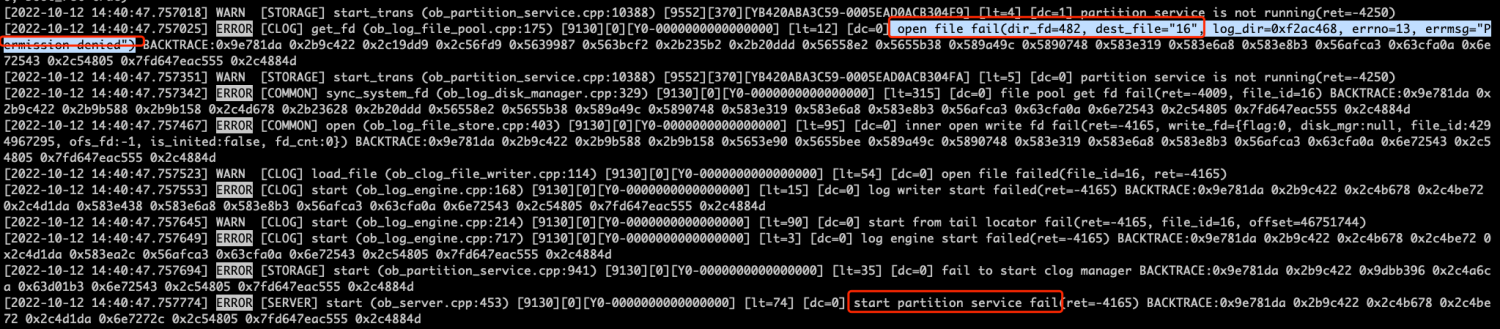
ERROR [COMMON] inner_open_fd (ob_log_disk_manager.cpp:1043) [5889][0][Y0-0000000000000000] [lt=5] [dc=0] open file fail(ret=-4009, fname="/home/admin/oceanbase/store/lzq/slog/4", flag=1069122, errno=13, errmsg="Permission denied") ERROR [SERVER] init (ob_server.cpp:172) [4195][0][Y0-0000000000000000] [lt=2] init config fail(ret=-4009)
可能原因
OCP 部署或接管的 OceanBase 集群均是 admin 用户权限,使用 root 启用后会导致 observer.conf.bin 文件和 redo 日志目录下的文件权限变更,无法再使用 admin 启动成功。
解决方案
执行如下命令修改所有 OBServer 节点目录的权限。
chown -R admin.admin /home/admin/oceanbase/ chown -R admin.admin /data/1 chown -R admin.admin /data/log1
问题现象
使用 OCP V3.3.0 部署 OceanBase 数据库时安装路径检测失败。
可能原因
安装目录和数据目录没有 admin 用户权限。
解决方案
可执行如下命令为安装目录和数据目录赋予 admin 用户权限。
chown -R admin:admin /data && chown -R admin:admin /redo && chown -R admin:admin /home/admin
问题现象
使用 OCP V3.3.0 接管使用 OBD 部署的 OceanBase V4.0.0 集群时失败,报错
(conn=10) Table 'oceanbase.v$ob_cluster' doesn't exist。可能原因
OceanBase 数据库 4.0.0.0 版本相较 3.x 版本架构变动较大,部分系统表进行调整,使用不配套的 OCP 版本无法接管。
解决方案
可升级 OCP 版本到 V4.0.0。
问题现象
无法使用 OCP 把管理的 OceanBase 数据库移除。
适用版本
OCP 3.x、4.x 版本。
可能原因
OCP 暂不支持迁出部署和接管的集群,但可以使用接口实现,并且迁出的集群不管是使用 OBD 部署的还是使用 OCP 部署的,均支持再次接管。后续版本会增加迁出集群功能。
解决方案
可以通过调用后端 restful api 的方式来迁出 OceanBase 数据库集群。命令如下:
curl -X POST --user {user}:{password} -H "Content-Type:application/json" -d '{}' "http://{ocp-url}:{port}/api/v2/ob/clusters/{cluster_id}/moveOut" # example curl -X POST --user admin:aaAA11__ -H "Content-Type:application/json" -d '{}' "<http://10.10.10.1:8080/api/v2/ob/clusters/2/moveOut>"需注意的是,命令中的 cluster_id 指的是 OCP 浏览器地址中的集群 ID,例如xx.xx.xx.xx:8080/cluster/2,表示 cluster_id 是 2。
问题现象
使用 OCP V3.3.0 重启 OceanBase(V3.1.4)集群被卡住,该集群使用 OBD 可正常重启。
查看日志报错:Connect to xx.xx.xx.xx:62888 [/xx.xx.xx.xx] failed: Connection refused (Connection refused)
可能原因
ocp-agent 服务的端口为 62888,查看日志显示报错连接被拒绝,基本为 ocp-agent 服务异常无法通过 agent 服务下发指令导致。
解决方案
重启主机节点的 ocp-agent 服务。
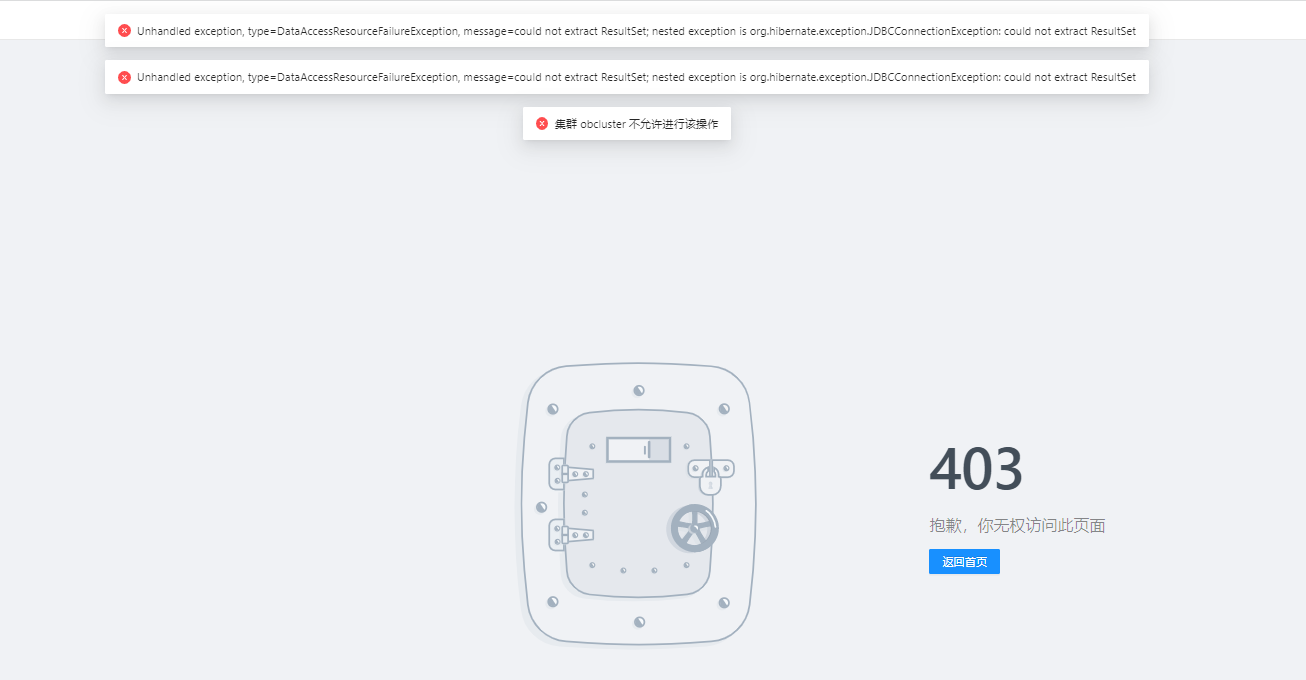
问题现象
使用 OCP V4.0 关闭集群页面报错:集群 obcluster 不允许进行操作。
可能原因
OCP 的 metadb 被 OCP 自身接管,如果使用 OCP 管理该集群会导致 OCP 服务不可用。
解决方案
不能使用 OCP 停止接管的 metadb。
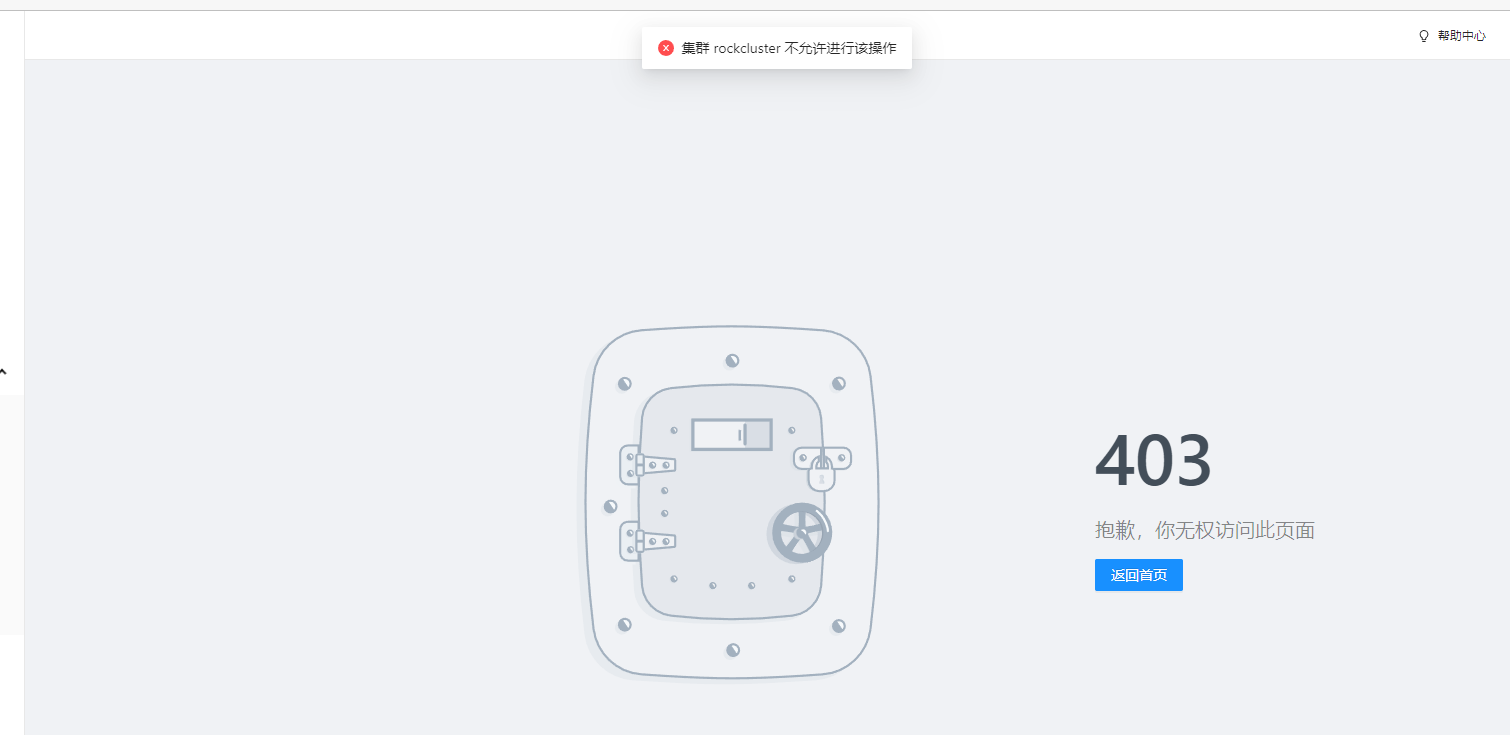
问题现象
使用 OCP 4.x 版本删除租户下的 test1 库,提示不允许进行该操作。
可能原因
此集群和 metadb 共用,OCP metadb 默认是不允许通过 OCP 做运维操作的。
解决方案
OCP meta 租户下执行如下命令将黑名单对应的 value 置空。
update config_properties set value='' where `key`='ocp.ob.cluster.ops.blacklist';
问题现象
将 OCP 从 V3.1.1 升级至 V3.3.0 时失败,报错 yaml 格式不正确。
可能原因
OCP V3.1.1 和 V3.3.0 的配置文件格式差异较大,升级需要使用 V3.3.0 的配置格式。
解决方案
按 OCP V3.3.0 的配置模版文件改写。
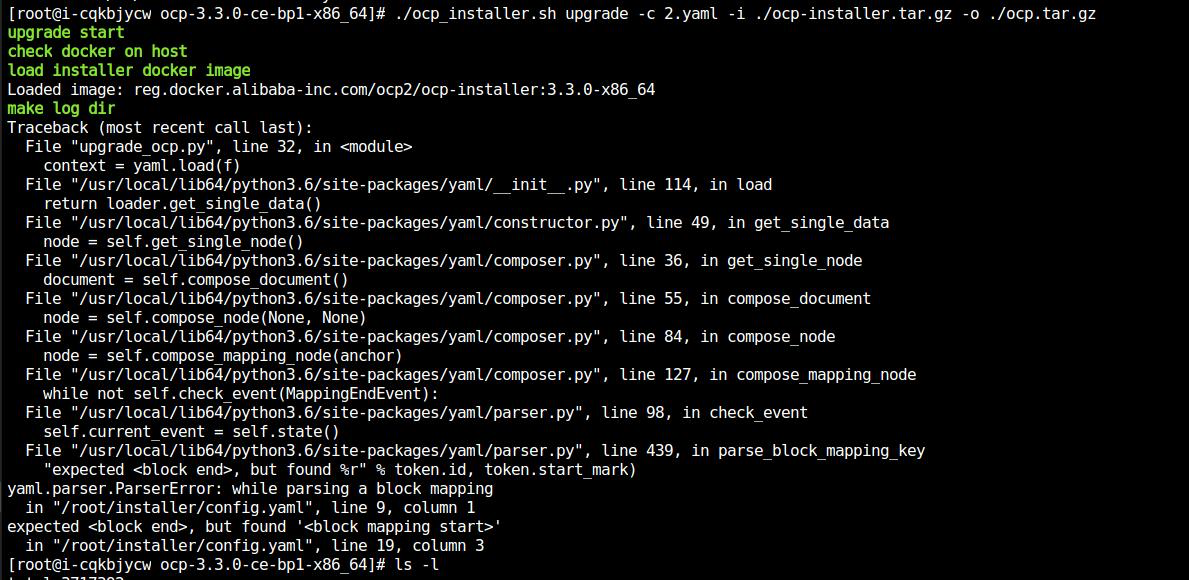
问题现象
OCP 从 V3.1.1 升级至 V3.3.0 失败,使用 OBProxy 配置测试可以连接,但升级报错连接不上
metadb:Can't connect to MySQL server on xx.xx.xx.xx:2883(-2 Name or server not know)。
可能原因
本示例中 107 机器是 OBProxy 的地址,非 metadb 地址,程序的这一步是要 ssh 到 OCP 节点 IP,运行 OCP 的 Docker 命令指向的地址是该 IP,但 107 机器非 OCP 元数据库也非 OCP 地址,所以报错连不上,因此不能使用非 metadb 本机的 OBProxy 地址。当然这里的版本升级也不建议使用 OBProxy 代理方式连接。
解决方案
该版本未支持采用 OBProxy 方式连接 metadb,配置改为使用直连方式。
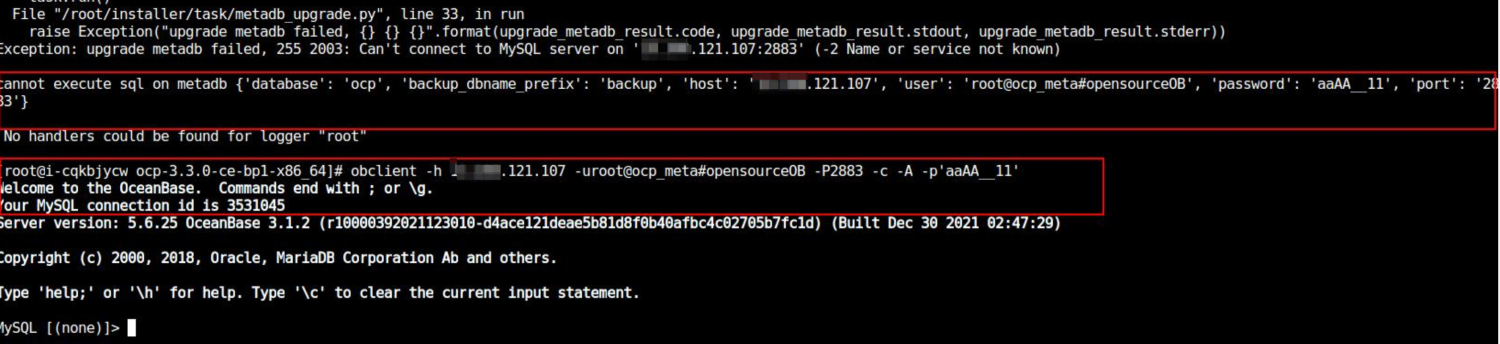
问题现象
将 OCP 从 V3.1.1 升级至 V3.3.0 报错
Can't connect to MySQL server on xx.xx.xx.xx:2881(-2 Name or server not know)。
可能原因
OCP V3.1.1 配置是直连方案,V3.3.0 配置是 proxy 连接方案,升级需要保持原方案,直连时用户名不能带集群名称,否则会被误把 “租户#集群名称” 解析成租户。
解决方案
在 yaml 配置文件 metadb 模块使用直连方式,去掉租户的
#集群名称。

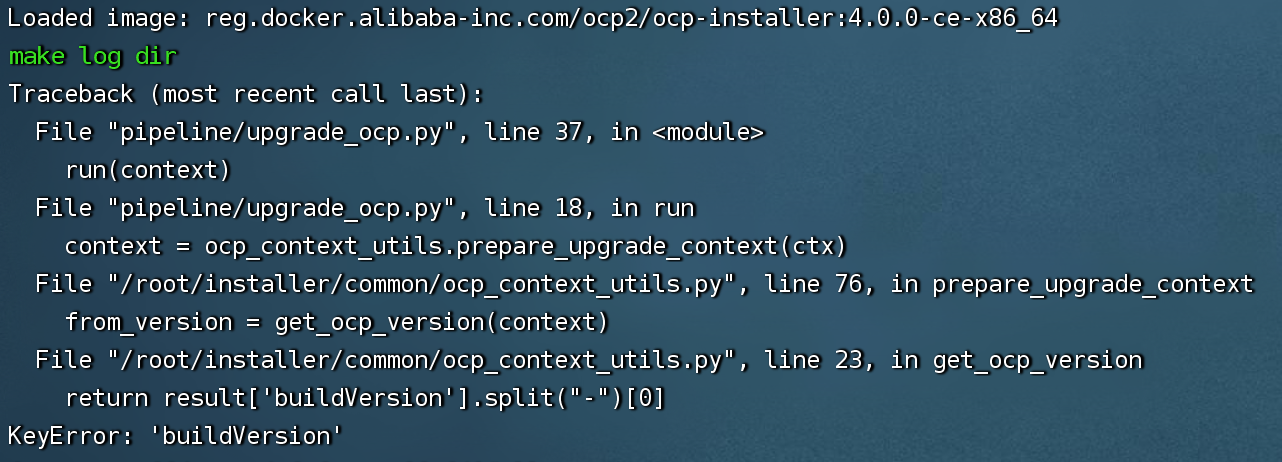
问题现象
将 OCP 从 V3.3.0 升级到 V4.0.0 报错
KeyError: 'buildVersion'。
可能原因
升级需要调用接口连接 OCP,使用的账户为配置文件中的 auth 模块信息,auth 模块配置只有升级过程会用到。如果通过 OCP 白屏修改过登录密码,该配置中也需同步修改。
解决方案
cinfig.yaml 文件 auth 模块的信息改为 OCP 白屏登录用户和密码。
OMS 使用问题 #
问题现象
使用 OMS V3.3.1 在迁移多张大表到 OceanBase 数据库时,checker 组件报错
NNER_ERROR[CM-RESONF000003]: no enough host resource for a CHECKER, reason [host: IP unavailable cause: current memory usage 0.8573829 exceed limited 0.85]。可能原因
迁移大表较多,使用默认的 checker 组件资源过小。
解决方案
迁移项目详情页点击 查看组件监控,更新 checker 配置中的
task.checker_jvm_param调整 jvm 参数。
问题现象
使用 OMS V3.3.0 启动增量同步报错
INVALID_STATUS_ERROR [INVALID_STATUS_ERROR] {“message”:“Not found ocp name from connectInfo: jdbc:oceanbase://xx.xx.xx.xx:2883?allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false&useSSL=false”}。可能原因
使用 OMS 启动增量任务时没找到 OCP 或者 configUrl,检查一下数据源里有没有配置 OCP 或者 configUrl。
解决方案
在数据源的高级选项里配置 configUrl。
OBProxy 问题 #
问题现象
使用 OBProxy 4.x 版本做大批量插入时候,应用报错
Connection reset by peer。OBProxy 日志中看到报错:obproxy’s memroy is out of limit’s 80% !!!
可能原因
通过报错信息看是 OBProxy 的内存超出了,但最终问题是现场插入是未做连接回收引发多种问题,可以借鉴。
解决方案
使用 root@proxysys 账号 2883 端口连接到 OBProxy,修改内存大小:
ALTER proxyconfig SET proxy_mem_limited = 6G;。
ODC 问题 #
问题现象
使用 MAC 安装 ODC V3.3.2 报错
[com.alipay.odc.config.BeanCreateFailedAnalyzer][21]: bean create failed。可能原因
有可能是 JAVA 版本的问题。
解决方案
推荐使用自带 JDK 的版本。
问题现象
ODC 新建连接报错
BadRequest exception, type=IllegalArgumentException, message=Not a valid secret key。适用版本
ODC 3.x 版本。
可能原因
可能由于 JRE 版本过低,出现加密失败导致。
解决方案
可以下载最新 ODC 版本,推荐使用内置 jre 的 ODC 版本
问题现象
ODC V3.2.3 客户端报 Query timed out 错误。
报错:ErrorCode = 1317, SQLState = 70100, Details = (conn=405741) Query timed out
可能原因
ODC 工具自身有个 “SQL 查询超时时间” 设置,这里是 SQL 的执行时间超过了 ODC 在驱动层设定的超时时间导致。
解决方案
需要在 连接详情 界面更改 “SQL 查询超时时间”,使其大于 SQL 的实际执行时间。
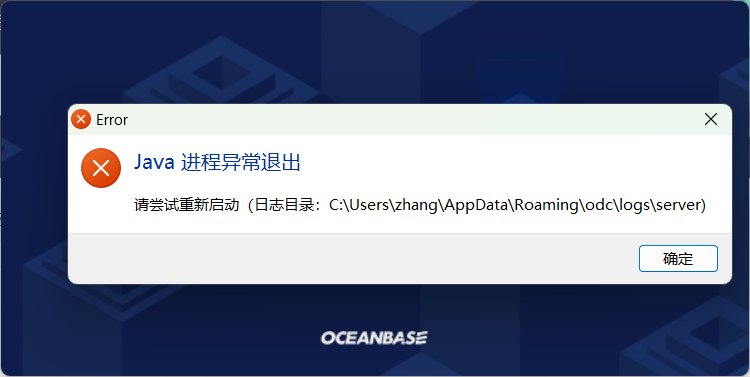
问题现象
刚部署的 ODC(V3.2.3) 打开保存 Java 进程异常退出。
报错:Error creating bean with name ‘dataSource’ defined in class path resource [org/springframework/boot/autoconfigure/jdbc/DataSourceConfiguration$Hikari.class]: Initialization of bean failed; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name ‘org.springframework.boot.autoconfigure.jdbc.DataSourceInitializerInvoker’: Invocation of init method failed; nested exception is org.springframework.jdbc.datasource.init.UncategorizedScriptException: Failed to execute database script; nested exception is org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is org.h2.jdbc.JdbcSQLNonTransientException: General error: “java.lang.IllegalStateException: Chunk 3233 not found [1.4.200/9]” [50000-200]
可能原因
ODC 桌面版使用的是 h2 作为内置数据源,但是 h2 bug 比较多,不大稳定,可能会出现数据损坏的问题,这就会导致 ODC 无法打开,出现截图中问题。
通常来说 h2 数据文件损坏是由于不正常关闭软件导致,比如 ODC 没有退出就直接关机,任务管理器直接终止进程等等。
解决方案
在 ODC 安装目录下删除 odc2.x.mv.db,odc2.0.trace.db,之后重启。
OBDUMPER/OBLOADER 使用问题 #
Q:如何解决使用 OBLOADER 导入时遇到 OOM 错误?
A:首先修改 bin/obloader 脚本中的 JAVA 虚拟机内存参数。其次排除 OpenJDK GC Bug。
Q:如何在调试模式下运行 OBLOADER 排查问题?
A:直接运行 bin/obloader-debug 进行导入。
Q:如何使用 OBLOADER 导入与表不同名的数据文件?
A:命令行中的-f选项指定为数据文件的绝对路径。例如:–table ’test’ -f ‘/output/hello.csv’。
Q:为表配置了控制文件,导入的数据为什么没有生效?
A:要求控制文件的名称与表名相同且大小写一致。MySQL 默认表名为小写,Oracle 默认表名为大写。
Q:运行 OBLOADER 脚本时,命令行选项未被正常解析的原因是什么?
A:可能是命令行参数值中存在特殊符号。例如:Linux 平台上运行导数工具,密码中存在大于号(注:> 是重定向符),导致运行的日志都会出现丢失。因此在不同的运行平台使用正确的引号进行处理。
- Windows 平台参数使用双引号。例如:–table “*"。
- 类 Linux 平台参数使用单引号。例如:–table ‘*’。
Q:运行 OBLOADER 脚本时,何时需要对参数加单引号或者双引号?
A:建议用户在一些字符串的参数值左右加上相应的引号。
- Windows 平台参数使用双引号。例如:–table “*"。
- 类 Linux 平台参数使用单引号。例如:–table ‘*’。
Q:外部文件格式不符合要求导致导入失败,应该如何解决?
A:导入外部文件时对格式有以下要求:
- 外部文件如果为 SQL 文件,要求 SQL 文件中不能有注释和 SET 开关语句等,并且文件中只能有 INSERT 语句,每条语句不可以换行。除此以外,文件中存在 DDL 或者 DML 语句,建议使用 MySQL source 命令导入。
- 外部文件如果为 CSV 文件,CSV 文件需符合标准定义。要求有转义符、定界符、列分隔符和行分隔符。数据中存在定界符需要指定转义符。
Q:OBLOADER 启动报错 Access denied for user ‘root’@‘xxx.xxx.xxx.xxx’。
A:导数工具默认依赖 root@sys 用户和密码。如果集群中已为 root@sys 用户设置的密码,请在命令行中指定--sys-password选项的参数值为 root@sys 用户设置的密码。
Q:OBLOADER 运行报错 Over tenant memory limits 或者 No memory or reach tenant memory limit。
A:调大全局 SQL 工作区的内存比例或者减少 –thread 并发数,例如。
set global ob_sql_work_area_percentage=30; – Default 5
Q:OBLOADER 运行报错 No tables are exists in the schema: “xxx”。
A:–table ’t1,t2’ 选项指定的表名一定是数据库中已经定义的表名,且大小写需要保持一致。MySQL 模式下默认表名为小写,Oracle 模式下默认表名为大写。如果 Oracle 中定义的表名为小写,表名左右需要使用中括号。例如:–table ‘[t1]’ 表示小写的表名。
Q:OBLOADER 运行报错 The xxx files are not found in the path: “xxx”。
A:要求-f指定的目录中的数据文件的名称与表名相同且大小写一致。MySQL 模式下默认表名为小写,Oracle 模式下默认表名为大写。例如:–table ’t1’目录中的数据文件须为 t1.csv 或者 t1.sql,不能是 T1.csv 或者其它的文件名。
Q:OBLOADER 运行报错 The manifest file: “xxx” is missing。
A:元数据文件 MANIFEST.bin 是 OBDUMPER 导出时产生的。使用其它工具导出时没有元数据文件。通过指定--external-data选项可跳过检查元数据文件。
Q:OBLOADER 导入 Delimited Text 格式时报错 Index:0,Size:0。
A:出现这种错误的原因是数据中存在回车符/换行符,请先使用脚本删除数据中的回车符/换行符后再导入数据。
Q:OceanBase 数据库 MySQL 模式下,连接 ODP (Sharding) 逻辑库导入 KEY 分区表数据时,OceanBase Database Proxy (ODP) 显示内存不足且 OBLOADER 运行报错 socket was closed by server。
A:设置 proxy_mem_limited 参数的权限,确认是否有外部依赖,ODP 默认内存限制为 2GB。连接 ODP (Sharding) 逻辑库且通过 OBLOADER 导入数据时需要使用 root@proxysys 账号权限,修改逻辑库内存限制语句如下。
ALTER proxyconfig SET proxy_mem_limited = xxg;
Q:如何解决使用 OBDUMPER 导出时遇到 OOM 错误?
A:首先修改 bin/obdumper 脚本中的 JAVA 虚拟机内存参数,其次排除 OpenJDK GC Bug。
Q:如何在调试模式下运行 OBDUMPER 排查问题?
A:直接运行 bin 目录下的调试脚本,例如:obdumper-debug。
Q:为表配置了控制文件,导入或者导出的数据为什么没有生效?
A:要求控制文件的名称与表名相同且大小写一致。MySQL 默认表名为小写,Oracle 默认表名为大写。
Q:OBDUMPER 导出数据时,为什么空表未产生空数据文件?
A:默认空表不会产生对应的空文件。--retain-empty-files选项可保留空表所对应的空文件。
Q:OBDUMPER 运行脚本时,命令行参数未被正常解析的原因是什么?
A:可能是命令行参数中存在特殊符号。Linux 平台上运行 OBDUMPER,密码中存在大于号(> 是重定向符),导致运行的日志出现丢失。因此在不同的运行平台请使用正确的引号。
- Windows 平台参数使用双引号。例如:–table “*"。
- 类 Linux 平台参数使用单引号。例如:–table ‘*’。
Q:OBDUMPER 指定 –query-sql ‘大查询语句’ 导出数据过程中报错
Connection reset。
A:登入 sys 租户,将 OBProxy 配置参数client_tcp_user_timeout和server_tcp_user_timeout设置为 0。
Q:OBDUMPER 启动报错 Access denied for user ‘root’@‘xxx.xxx.xxx.xxx’。
A:OBDUMPER 默认依赖 root@sys 用户和密码。如果集群中已为 root@sys 用户设置密码,请在命令行中输入--sys-password选项并指定正确的 root@sys 用户的密码。
Q:OBDUMPER 运行报错 The target directory: “xxx” is not empty。
A:为防止数据覆盖,导出数据前,OBDUMPER 会检查输出目录是否为空(使用--skip-check-dir选项可跳过此检查)。
Q:OBDUMPER 运行报错 Request to read too old versioned data。
A:当前查询所依赖的数据版本已经被回收,用户需要根据查询设置 UNDO 的保留时间。 例如:set global undo_retention=xxx。默认单位:秒。
Q:OBDUMPER 运行报错 ChunkServer out of disk space。
A:由于 _temporary_file_io_area_size 参数值过小引起存储块溢出错误,可修改该系统配置参数,例如。
使用SELECT * FROM oceanbase.__all_virtual_sys_parameter_stat WHERE name='_temporary_file_io_area_size';命令查询该参数值,并使用ALTER SYSTEM SET _temporary_file_io_area_size = 20;命令修改该参数值。
Q:OBDUMPER 查询视图报错 SELECT command denied to user ‘xxx’@’%’ for table SYS.XXX。
A:由于用户无访问内部表或者视图的权限,需要运行语句GRANT SELECT SYS.XXX TO xxx;为用户进行授权。
Q:obloader 怎么一次性加载多个文件导入?
A:数据文件放置一个文件夹内,-f参数指定文件夹即可。
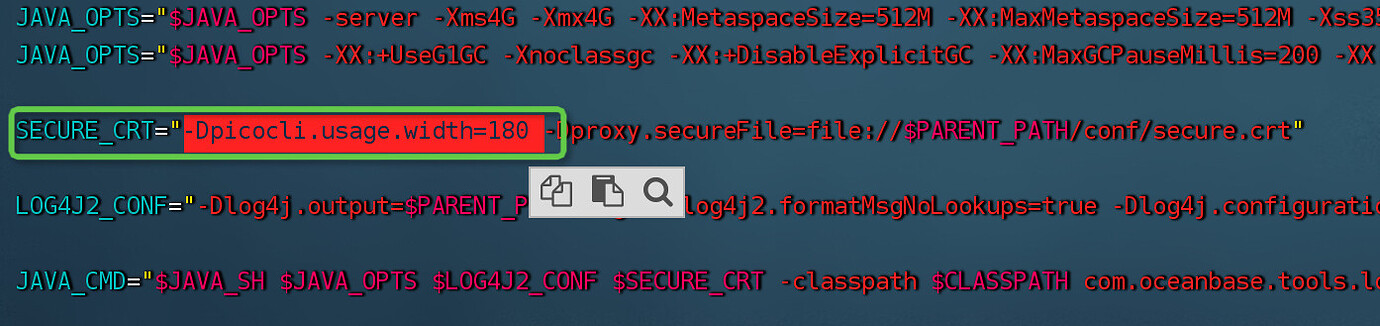
问题现象
使用 obloader V3.0.0 执行
obdumper --version命令时报错Invalid usage long options max width 60. Value must not exceed width。可能原因
已知的命令行框架 bug,obloader V4.0.0 已修复。
解决方案
如图所示,编辑 obdumper 脚本,增加参数
-Dpicocli.usage.width=180。
问题现象
使用 obloader V3.0.0 执行 obloader 导入时遇到报错
Invalid usage long options max width 60. Value must not exceed width(55) - 20。可能原因
已知的命令行框架 bug,obloader V4.0.0 已修复。
解决方案
可在运行脚本中添加 jvm 启动参数
-Dpicocli.usage.width=180。

OBLOGPROXY 部署问题 #
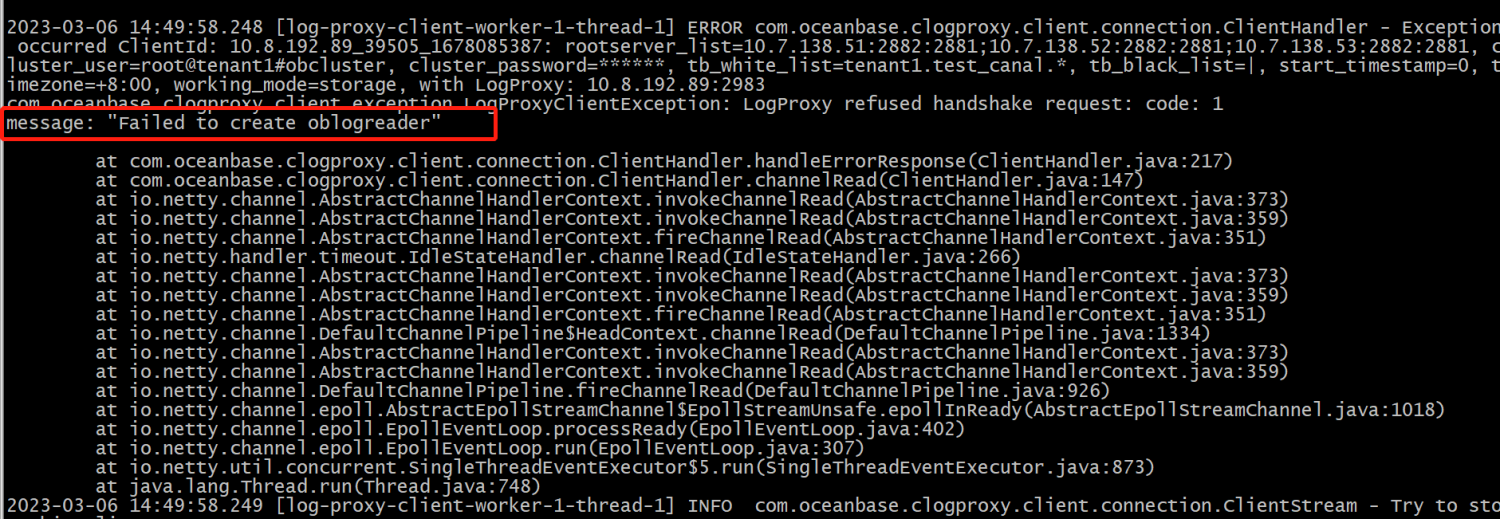
问题现象
使用 Canal 同步 OceanBase 数据库数据,oblogproxy 部署后,oblogreader 进程未启动,并可以查看到报错
Failed to create oblogreader。所用产品版本为 OceanBase 数据库 V4.0 ,oblogproxy V1.0.0。
可能原因
oblogproxy V1.0.0 与 OceanBase 数据库 3.x 版本适配,使用 OceanBase 数据库 4.0 版本时建议使用 oblogproxy V1.1.0 及以上版本。建议使用 oblogproxy 最新版本。
解决办法
使用最新 oblogproxy 版本即可。
其他 #
问题现象
使用 OBD V1.5.0 版本执行 mysqltest 失败,报错
mysqltest: At line 85: Version format 4 has not yet been implemented。可能原因
获取的 mysqltest 的二进制版本不是最新的,可以更新 OBClient,获取最新的 mysqltest 可执行文件。
解决方案
更新为最新的 OBClient。
问题现象
使用 dbcat 迁移数据到 OceanBase 数据库(3.1.x 版本)时报错
The table charset: ''latin1" is unsupported in OBMYSQL_2.2.50(2.2.50). Object: test.t2。可能原因
OceanBase 数据库 3.x 社区版本支持的字符集非常有限,当从 MySQL 中导出数据时,要确保数据库里的字符都能正确输出到文件中。通过 vim 命令下的
:set fileencoding命令可以查看文件的编码,一般建议都是 utf-8。 这样通过文件迁移MySQL数据时就不会出现乱码现象。解决方案
社区版 4.x 版本后常见的字符集基本上都支持了,可使用最新的 OceanBase 数据库 4.x 社区版本,或者保证字符集保持一致。可修改 /etc/my.cnf 文件,参考文档: centos 修改 mysql 字符集 - 一像素 - 博客园。
如果上述无法解决,可能是因为只修改了数据库编码,而表的默认编码没有修改,可再执行
alter table t1 convert to charset uft8;命令。如果仍无法解决可重新创建数据库,创建时就指定好编码,涉及命令:
create database test character set utf8 collate utf8_general_ci;。